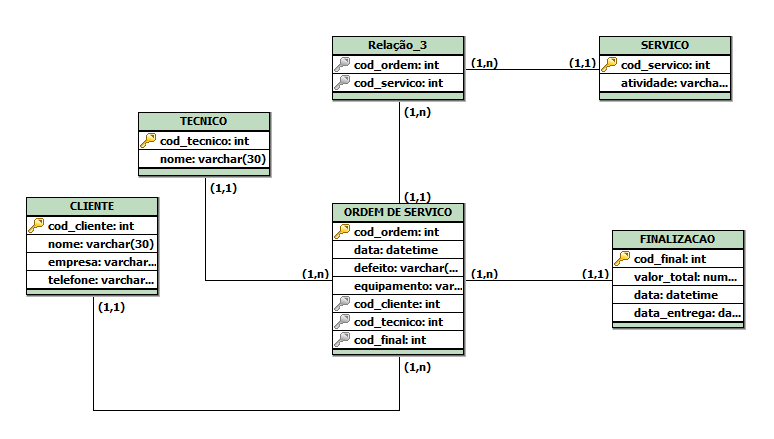
No relacionamento Finalizacao e Ordem_Servico (na imagem coloquei como Ordem de Servico, falha minha) deixei como (1:n), porém não sei se está correto. Po exemplo, depois de gerar uma OS, deverá ser possível que no sistema haja uma opção para finalizar a OS, e quando esta for finalizada, não poderá ser mais editada, etc… Desta forma, eu criei a tabela Finalizacao, que ao meu ver, deveria ter uma chave PK e FK ao mesmo tempo da tabela Ordem_Servico.
Acredito que esteja errado, pois o processo de finalização deverá só ser em cima de uma ordem de serviço a menos que seja possivel finalizar diversas ordens e ficar tudo registrado em uma finalização x.
Hmm… Entendi. A minha ideia é que uma ordem de serviço X seja finalizada por “finalização” X, e assim por diante. No caso, me vem a cabeça em usar relacionamento (1:1), mas aí eu teria que usar tabela única e ficaria uma confusão só.
Tem alguma outra forma?
Nos 2 casos são tabelas diferentes a unica coisa que muda em relação do exemplo 1 e 2 é…Ordem Service na 1 pode ter uma finalização.
Enquanto no exemplo 2, 2 Ordem_Service Diferentes apontam para mesma finalização.
Assim sendo, quando fizer uma query seguindo o primeiro exemplo:
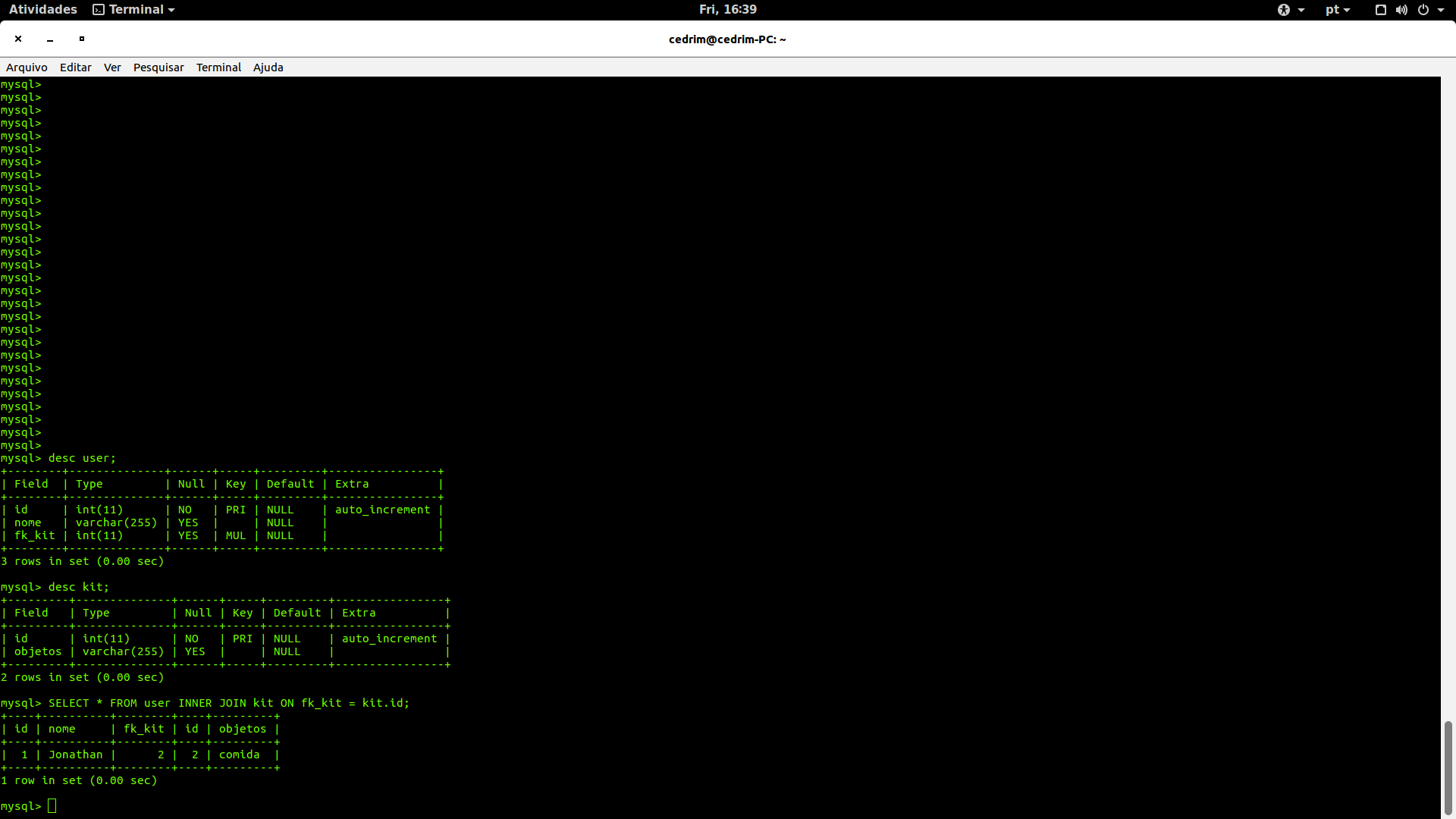
SELECT * FROM ordem_service INNER JOIN finalizacao ON cod_ordem = cod_final;
ele te retornara a ordem junto com a finalização
No segundo caso ele retornara 2 ordem diferente para uma mesma finalização.
Mas em ambos os casos 1…1 ou n…n sempre existiram tabelas únicas para cada entidade.
Ah, sim!! No meu caso, procuro por algo como o primeiro exemplo, onde cada ordem de serviço terá sua própria finalização. Em relação a “tabela única” que mencionei, quero dizer que eu teria que juntar as duas tabelas: Ordem_Servico e Finalizacao.
Acabei errando quanto ao relacionamento, o correto seria “fusão de tabelas”.
Então não faz sentido eu usar uma chave estrangeira e primária ao mesmo tempo?
Não é uma funsão, é você que modela a saída dela, por exemplo, utilizando o INNER JOIN ele ira mesclar os conjuntos que forem iguais nas duas tabelas dependendo da sua condição, Mas ai você decide como fica na hora.
No caso da chave primaria e estrangeira, não. Chave Primeira é o identificador da entidade em sua própria tabela, chave estrangeira é o identificador único de uma entidade externa em sua tabela.
Por fim, ainda sou novato,Então estou enquadrando tudo com o conhecimento que tenho agora. TT
Valeu!! Já me ajudou bastante. Eu fiquei com essas dúvidas, pois já vi exemplos semelhantes, mas não me lembro exatamente da aplicação deles na “prática”. Mas irei fazer da forma que me mostrou, achei interessante e está dentro do que eu quero. xD
Amigo não é julgamento é realmente uma pergunta da pergunta!
Eu que trabalho hoje com camada de persistência isso ai não é muito bom fazer! mas, eu queria ouvir as opiniões do pessoal era só isso mesmo … sem problemas!
Fiquei curioso sobre isso também. Não sei se entendi, mas ao invés de “id_cliente” seria puramente “id” na tabela? Se for isso, também prefiro usar “id_cliente”, senão o SQL fica com um bando de "id"s, nos selects e joins, se referindo a várias tabelas diferentes. Por mais que tenha “alias”, fica confuso de ler imediatamente de que tabela o id se refere, principalmente em relatórios com SQLs complexos. Claro que não existe mundo perfeito e cada equipe decide o que julgar mais confortável, mas eu já passei por isso de usar “id” puro e achei mais confuso do que da forma “tradicional”, pelo menos para quem só usa banco de dados relacional diretamente via SQL, sem “overengineering” de recursos intermediários para gerar SQLs via ORMs pesados.
Cara, a parte do “Não me julgue” foi uma ironia minha! Kkkkkkk
Outro membro do fórum já tinha me alertado sobre a nomenclatura que eu utilizava… Mudei bastante ela, e realmente, deixou meus projetos bem melhores, mais organizados. A questão dos IDs é pelo motivo que citei, algo meu, pessoal…
Claro, se eu estiver num projeto que envolvam outros membros, numa empresa, etc., usarei o que é descrito nos diversos padrões de projetos.
Mas aproveitando o tópico. Poderia me dizer alguns motivos pelos quais não é bom utilizar “id_cliente, id_isso, id_aquilo”?
Para você ter idéia é uma assunto de gosto e pode virar polêmica, mas, eu por exemplo sempre uso assim, exemplo:
Tabela Cliente
Campos Id Nome DataCriacao
Tabela Noticia
Campos Id Titulo ClienteId (relação com a tabela de Cliente
e nunca tive problema, claro que talvez eu faço alguns alias (as) algumas vezes, mas, nunca me atrapalhou o fato de identificar a tabela dessa forma.
Já use assim também:
Tabela Cliente
Campos ClienteId Nome DataCriacao
Tabela Noticia
Campos NoticiaId Titulo ClienteId (relação com a tabela de Cliente
também nunca me atrapalhou, principalmente por vários fatores inclusive também por utilizar Camadas de Persistências e Micro ORM (que tem ótimo desempenho como Dapper por exemplo), mas, eu percebo assim que ainda tem bastante gente utilizando a maneira com underscore e nome conjuntos sendo que a tabela já é o nome, exemplo Cliente.ClienteId.
Em relação aos Joins da vida (kkkk) eu sempre otimizo o máximo que posso de SQL não trago tudo só o que é necessário e muitas vezes vejo SQL muitos erradas como Select a.*, b.* From pessoa a inner join cliente b on b.id = pessoa.clienteid e por isso o choque de Id neh!
Só queria relatar que isso é um debate, acredito ser de grande valia quem puder participar … e dar sua contribuição, o que mais percebo que não existe uma nomenclatura padrão, mas, sim um jeito que eu gosto de usar!
Na verdade eu acredito que isso seja o gosto e a forma que você programa, eu fiz o debate por não achar conveniente essa repitação, mas, claro não é errado ou certo, e sim maneiras que eu programo e os outros programa.
Eu por exemplo nunca vi ninguém dizer que existe um padrão de nomes para banco, talvez empresas criem o seu, mas, individualmente cada um faz a sua maneira.
Também uso Dapper em .NET, antes dele usava biblioteca que fazia o mesmo tipo de trabalho para ajudar nas partes que eram repetitivas com ADO.NET puro. Parabéns por evitar overengineering com Hibernate/NHibernate ou EF!
Em relação a ClientId ou IdCliente não tenho nada contra, somente em usar “id” puro.
Sobre duas tabelas iguais, isso não tem jeito mesmo, mas não é uma situação que acontece o tempo todo, me refiro a bater o olho em todas as querys e ver um bando de "id"s iguais, mesmo que tenha um alias.
O Dapper tem opção pra ignorar underscore. Gostaria muito de trabalhar sem underscore, mas por padrão não me é permitido. E acredito que ficaria confuso no banco, pelo menos no meu caso onde o schema não é case sensitive, ficaria esquisito clientid, razaosocial, exemplonomegrandequalquer, etc, entendeu?
Outro ponto, será que existe normativas para tal?
Sobre ORM é outro assunto polêmico! kkkkkkkkkk
Bom eu uso e não perco desempenho, o problema com ORM que o pessoa não sabe usar! um exemplo corriqueiro:
Entity Framework
db.Cliente.ToList().Where(x … (aqui já era o desempenho, porque o cara não faz where na SQL ele faz Where na mémoria e na carga total de dados, e isso eu vejo quase todos os dias !
Pois é, dependendo do porte da empresa isso ai pode derrubar uma aplicação! O que mais vejo em aplicações com NHibernate são problemas de n+1 query, uso de cache sem necessidade e por ai vai consumindo recursos sem necessidade, com pessoas experientes trabalhando no projeto, e eu tinha que seguir desse jeito para não ser “o diferente”. Só o fato de levantar e manter vivo um SessionFactory, é um peso que vem obrigatoriamente independente do quanto o programador será eficiente com o uso corriqueiro da ferramenta. O Dapper sozinho é leve pois não tem essas tranqueiras todas, é uma biblioteca simples para estender a DbConnection, mais para ajudar na parte repetitiva de hidratação de objetos, sem que o programador fuja de usar SQL diretamente, sem precisar de recursos OO intermediários para gerar o SQL.
Pra não generalizar expliquei os pontos que sou contra, onde por exemplo não é o caso de micro "ORM"s, que independente da sigla, são bibliotecas leves só para ajudar em partes repetitivas, não inclinando o programador a fazer querys intermediárias por meio de modelo orientado a objetos. Mas em se tratando de ORMs completos como Hibernate eu sou contra, por exemplo para backend HTTP com um SGDB relacional. Mas já teve suas vantagens para client/server, como uso de cache, lazy, etc, pois neste caso o hibernate ficava de fato no client, fazendo mais sentido o cliente tirar proveito desses recursos.