Não necessariamente, você está com o conceito de “uma palavra” fixo na cabeça, mas para a base de dados nã faz diferença, a mesma palavra várias vezes continua sendo registros diferentes pegou?
Me refiro ao relacionamento de campos mesmo, ou não existe?
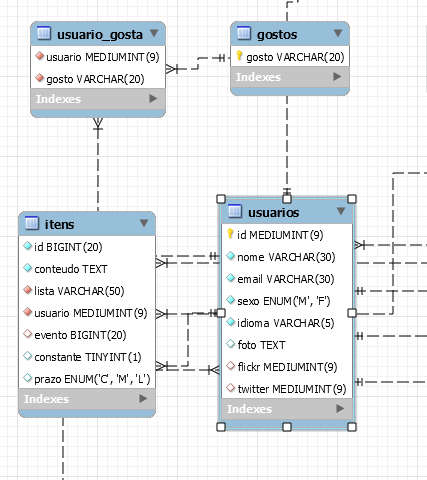
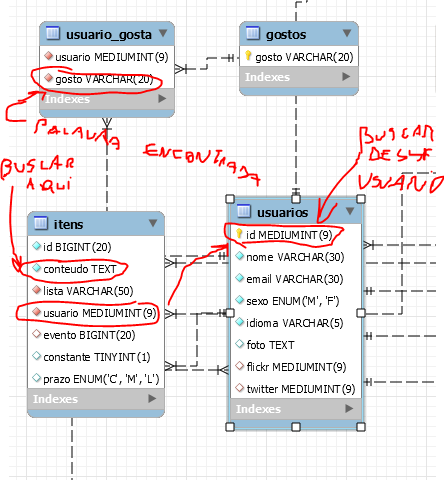
Por exemplo, na tabela itens existe algum campo (chave estrangeira) que indica qual seu usuário?
Se sim esse campo é um int representando um código, é o cpf do usuário, rg ou o quê?
Para facilitar a comunicação, o workbench dispõe de uma ferramenta que faz a engenharia reversa da base, ou seja, traz do físico para o papel e monta um MER (modelagem entidade e relacionamento), e dependendo de como você configurou as tabelas, traz até os relacionamentos…
Pesquise e se conseguir gerar tira um print e manda pra gente ver e ter uma visão “panorâmica” do seu projeto…