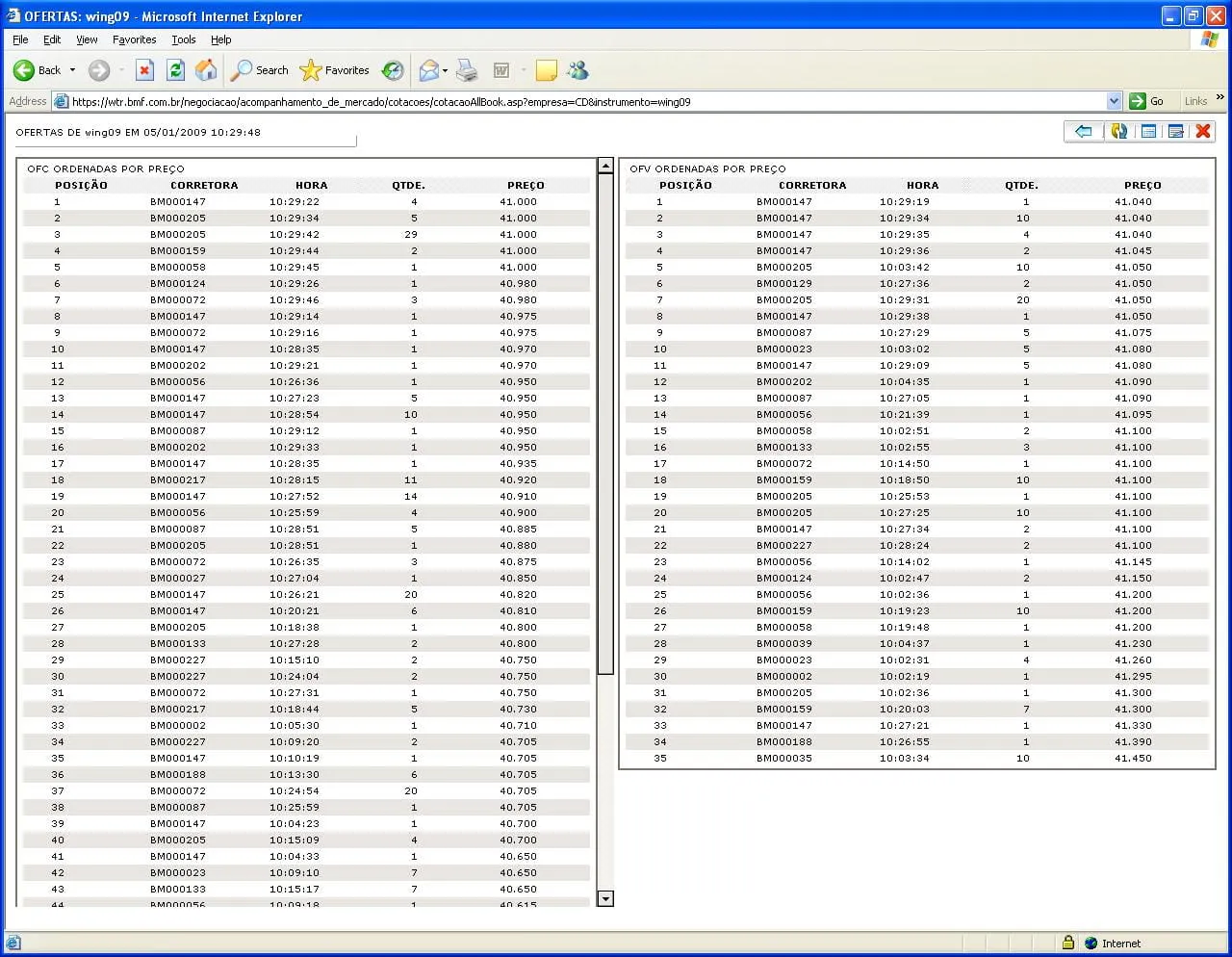
Galera estou com um problema. Eu preciso pegar algumas informacoes de um site de ofertas de compra e venda de minicontratos de ibovespa futuro. Eu consigo puxar o codigo fonte mas eu nao consegui achar nada nele que fosse util. Eu nao nao entendo nada de JavaScrip, por isso nao consigo identificar muito bem o que esta escrito no codigo. Nao adianta eu passar o link para voces pois envolve login para acessar tal tela, coisa que eu consugo fazer com o meu programa. Eu vo deixar aqui postado o codigo fonte e um print em anexo. Se alguem tiverl alguma ideiae souber se eh possibel ou nao plz, me ajude!! Vlew!!
PS: Antes que falem que isso eh um forum de Java e nao de JavaScrip eu quero pegar essas informacoes com o meu programa em Java.
Codigo Fonte:
<HTML>
<HEAD>
<META NAME="GENERATOR" Content="Microsoft Visual Studio 6.0">
<title>OFERTAS: wing09</title>
<link href="/negociacao/CSS/27.css" rel="stylesheet" type="text/css">
<script type="text/javascript" src="/negociacao/JS/funcoes.js"></script>
<script>
//parametros
var iCulture = 1;
var sEmpresa = "CD";
var sInstrumento = "WING09";
var sApplicationPath = "/negociacao";
var sSkin = "27";
function Search(code)
{
if (code == '' ) {
alert("Código do instrumento inválido (" + code + ").");
return;
}
window.location.href = "../cotacoesEmpresa.asp?ativo="+code;
}
function SendToForm(qty, value)
{
try
{
alert("Função indisponivel");
}
catch(e) {
alert("Erro: " + e);
}
}
//body (scope)
{
//General
var xmlelem, xmlnode, count;
var maxItm = 30;
var arrType = new Array("S","B");
//consulta de compra
var strXmlIn = "<BOOK><INST NAME=\"" + sInstrumento + "\" EXCH=\"" + sEmpresa + "\" QTTO=\"100\"/></BOOK>";
var strXmlErr = "<BOOK><INST NAME=\"" + sInstrumento + "\" EXCH=\"" + sEmpresa + "\"><ORDERS TYOR=\"S\"></ORDERS><ORDERS TYOR=\"B\"></ORDERS></INST></BOOK>";
//executar consulta
var xmldoc = executaXML(sApplicationPath+"/_xml/xml_consulta_livro_ofertas.asp", strXmlIn);
//se nao retornou nada, exibir xml default
if(xmldoc.xml == '')
{
xmldoc = new ActiveXObject("MSXML2.DOMDocument");
xmldoc.async=false;
xmldoc.loadXML(strXmlErr);
}
//preencher o grid se houver menos de 20 ofertas
for (var j=0; j < arrType.length; j++)
{
count = xmldoc.selectNodes("//BOOK/INST/ORDERS[@TYOR='" + arrType[j] + "']/ORDER").length;
if ( count >= maxItm )
continue;
xmlnode = xmldoc.selectSingleNode("//BOOK/INST/ORDERS[@TYOR='" + arrType[j] + "']");
if ( xmlnode != null )
{
for (var i = 0; i < (maxItm - count); i++)
{
xmlelem = xmldoc.createElement("ORDER");
xmlelem.setAttribute("PRCE","0");
xmlelem.setAttribute("QTOR","0");
xmlnode.appendChild(xmlelem);
}
}
}
}
function CreateBook(cType, xmlDocument)
{
//clonar estrutura
var xmlCopy = xmlDocument.cloneNode(4);
//selecionar nodes de venda para exclusao
var xmlNodeList = xmlCopy.selectNodes("//BOOK/INST/ORDERS");
for (var i = 0; i < xmlNodeList.length; i++)
{
if (xmlNodeList[i].attributes.getNamedItem("TYOR").nodeValue.toUpperCase() == cType )
{
var parent = xmlNodeList[i].parentNode;
parent.removeChild(xmlNodeList[i]);
}
}
//posicionar no root
var rootnode = xmlCopy.documentElement;
//adicionar data e hora atual
var oDataHora = xmlCopy.createElement("dataHora");
rootnode.appendChild(oDataHora);
rootnode.lastChild.text = '05/01/2009 10:29:48';
//adicionar skin
var oSkinAttrib = xmlCopy.createElement("skin");
rootnode.appendChild(oSkinAttrib);
rootnode.lastChild.text = sSkin;
//adicionar flag
var oTopTenAttrib = xmlCopy.createElement("TopTen");
rootnode.appendChild(oTopTenAttrib);
rootnode.lastChild.text = "1";
//aplicar XSL ao XML
var content = applyXSL(xmlCopy.xml, sApplicationPath + "/_xsl/xsl_consulta_livro_ofertas.xsl", iCulture, sApplicationPath);
//exibir
document.writeln( content );
}
</script>
</HEAD>
<BODY topmargin="0" bottommargin="0" leftmargin="10" rightmargin="10" scroll="no">
<table width="100%" border="0" cellpadding="0" cellspacing="0">
<tr>
<td colspan="2"><img src="/images/negociacao/skins/27/transp.gif" width="1" height="5"></td>
</tr>
<tr>
<td width="354" class="CON_TXT_PRETO">
<SPAN class=CON_TXT_PRETO>OFERTAS DE wing09 EM 05/01/2009 10:29:48</SPAN>
</td>
<td width="1" align="center" valign="bottom"><img src="/images/negociacao/skins/27/divideCinza.gif" width="1" height="11"></td>
<td height="29" align="right">
<table cellspacing=0 cellpadding=0 border=0>
<tr>
<td><a href="JavaScript:Search('wing09');"><img src="/images/negociacao/skins/27/btVoltar.gif" alt="Atualizar" border="0"></a></td>
<td><a href="JavaScript:window.document.location.reload();"><img src="/images/negociacao/skins/27/btTool_refresh.gif" alt="Atualizar" border="0"></a></td>
<!--td><img src="/images/negociacao/skins/27/btTool_NegDia.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/negocios.asp');" alt="Negócios do Dia" border="0" style="cursor:hand;"></td-->
<td><img src="/images/negociacao/skins/27/btTool_OrdPend.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/ordens.asp');" alt="Ofertas pendentes" border="0" style="cursor:hand;"></td>
<td><img src="/images/negociacao/skins/27/btTool_ModOferta.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/ordens.asp');" alt="Modificar oferta" border="0" style="cursor:hand;"></td>
<td><a href="JavaScript:window.close();"><img src="/images/negociacao/skins/27/btTool_close.gif" alt="Fechar" border="0"></a></td>
</tr>
</table>
</td>
</tr>
<tr><td class="DivCinza"><img src="/images/negociacao/skins/27/transp.gif" width="1" height="1"></td></tr>
<tr><td><img src="/images/negociacao/skins/27/transp.gif" width="1" height="10"></td></tr>
</table>
<table border="0" cellspacing="0" cellpadding="0" width="100%" height="92%">
<tr>
<!--PANEL LEFT-->
<td width="50%" valign="top">
<div class="scrollFull">
<span id="spnBuyOffers">
<script>CreateBook("S", xmldoc);</script>
</span>
</div>
</td>
<!--PANEL LEFT-->
<td> </td>
<!--PANEL RIGHT-->
<td width="50%" valign="top">
<div class="scrollFull">
<span id="spnSellOffers">
<script>CreateBook("B", xmldoc);</script>
</span>
</div>
</td>
<!--PANEL RIGHT-->
</tr>
</table>
</BODY>
</HTML>
A imagem esta em anexo!! Vlew!!
- Editado: inclusão da tag code - Rafael Carneiro