CONSIDERAÇÕES QUANTO AO LAÇO DE REPETIÇÃO FOR:
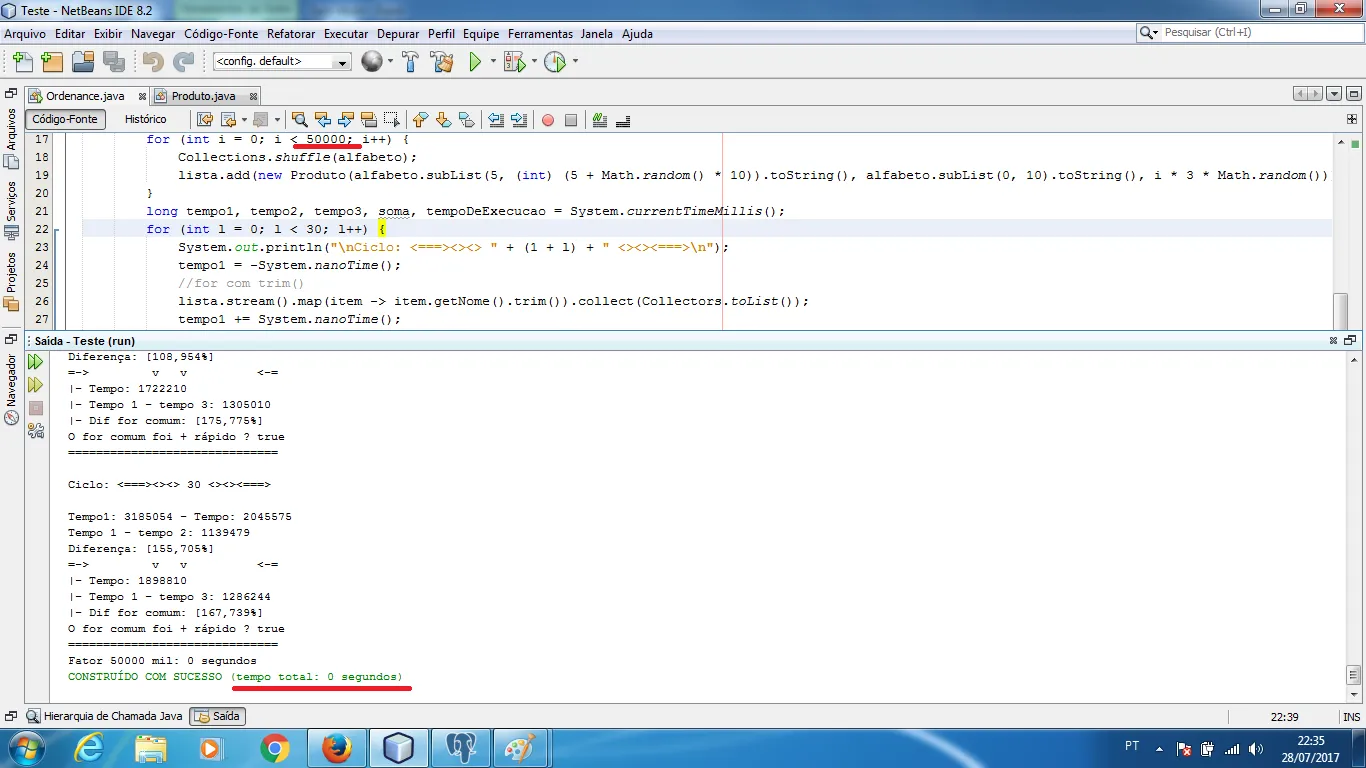
Não sou a pessoa mais indicada, entretanto, tenho em mente que em se tratando de desempenho, o for comum é muito poderoso.
Digo isto pois dos testes que fiz, o for comum levou a melhor em todos.
Uma vez fiz uma brincadeira de subtração de imagem usando for comum e para ver se dava pra otimizar, migrei a codificação para stream, ficou 20 mais lento.
Não é a última palavra, pois como disse não me considero a pessoa mais indicada.
Mas se tiver curiosidade você pode executar a seguinte codificação e ver por si mesmo.
import java.time.Duration;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
public class Ordenance {
public static void main(String[] args) {
ArrayList<String> alfabeto = new ArrayList<>(Arrays.asList(" ", " ", " ", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "r", "m", "n", "o", "p", "q", "r", "s", "t", "u", "x", "z"));
List<Produto> lista = new ArrayList<>();
//50000 esta levando menos de 1 segundo
for (int i = 0; i < 1000000; i++) {
Collections.shuffle(alfabeto);
lista.add(new Produto(alfabeto.subList(5, (int) (5 + Math.random() * 10)).toString(), alfabeto.subList(0, 10).toString(), i * 3 * Math.random()));
}
long tempo1, tempo2, tempo3, soma, tempoDeExecucao = System.currentTimeMillis();
for (int l = 0; l < 30; l++) {
System.out.println("\nCiclo: <===><><> " + (1 + l) + " <><><===>\n");
tempo1 = -System.nanoTime();
//for com trim()
lista.stream().map(item -> item.getNome().trim()).collect(Collectors.toList());
tempo1 += System.nanoTime();
tempo2 = -System.nanoTime();
//for sem trim()
lista.stream().map(Produto::getNome).collect(Collectors.toList());
tempo2 += System.nanoTime();
System.out.println("Tempo1: " + tempo1 + " - Tempo: " + tempo2+"\nTempo 1 - tempo 2: " + (tempo1 - tempo2)
+"\n"+String.format("Diferença: [%.3f", 100 * (float) tempo1 / tempo2) + "%]\n=-> v v <-=");
soma = 0;
tempo3 = -System.nanoTime();
//for comum
for (int j = 0; j < lista.size(); j++) {
soma += lista.get(j).getValor();
}
tempo3 += System.nanoTime();
System.out.println("|- Tempo: " + tempo3+"\n|- Tempo 1 - tempo 3: " + (tempo1 - tempo3)
+String.format("\n|- Dif for comum: [%.3f", 100 * (float) tempo1 / tempo3)
+ "%]\nO for comum foi + rápido ? "+(tempo3< tempo1 && tempo3 < tempo2)
+"\n==============================");
}
System.out.println("Fator 3 milhões: "+Duration.of(System.currentTimeMillis() -tempoDeExecucao, ChronoUnit.MILLIS).getSeconds()+" segundos");
}
}
public class Produto {
private String nome;
private String id;
private double valor;
public Produto(String nome, String id, double valor) {
this.nome = nome;
this.id = id;
this.valor = valor;
}
public String getNome() {
return nome;
}
public void setNome(String nome) {
this.nome = nome;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public double getValor() {
return valor;
}
public void setValor(double valor) {
this.valor = valor;
}
}
SUGESTÃO DE IMPLEMENTAÇÃO:
O problema não é consultar 50000, é o que se faz com esta consulta.
1 -p.setEstoqueSP(tot.find(ProdutoEstoque.class, Integer.parseInt(p.getCodigo().trim())));
a) o trim() consome muito recurso, pois ele vair percorrer uma string e remover o último caractere se for " ", o problema é fazer isto 50000 * o código que deve ser um número.
b) o Integer.ParseInt() vai tomar a parte dele no processamento.
c) não me ative as demais instruções nesta linha.
2 - p.setEstoqueSUM(tot.find(ProdutoEstoqueSUM.class, Integer.parseInt(p.getCodigo().trim())));
a) aparentemente faz outra consulta no banco de dados;
b) tome + trim() + Integer.ParseInt.
Sugestão:
Para corrigir item 1:
I) a interface de cadastramento não deve permitir a inserção de codificação com espaço no final, isto descartaria o uso de trim();
II) o banco de dados deve trabalhar com id numérico, portanto, não seria necessário usar o Integer.ParseInt.
III) ao invés da variável do tipo ResultSet pegar uma String no id, deve pegar um int como em seuResultSet.getInt(nomeOuNumeroDaColuna), pois assim, você teria o valor desejado com menos processamento.
Para corrigir o item 2:
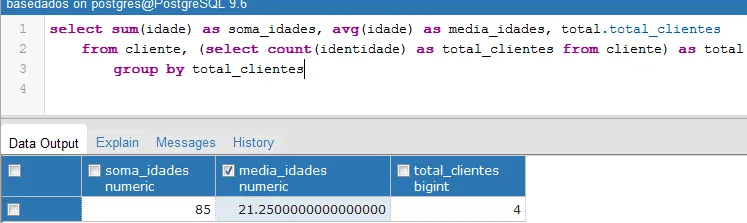
I) O banco de dados pode realizar a soma, media, outras contagens e formas de consulta que você necessitar, a exemplo de:
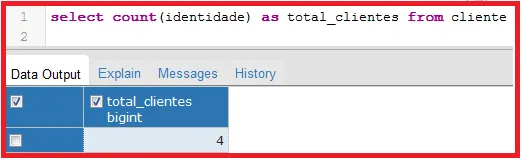
II) para contar os produtos, você precisaria de uma consulta simples, a exemplo de:
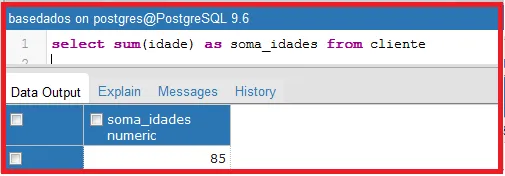
Obs.: se o cliente não vai visualizar 50000 itens, passe lotes de 50, 100, ou 200, e a medida em que o cliente vai visualizando, você vai realizando pequenas consultas no banco de dados e “populando” o view desejado.
Em se tratando de relatórios, faça uso do banco de dados e só passe pra frente o que for necessário.
Então, a melhor avaliação é o banco de dados pode estar sendo sub utilizado e está sobrecarregando a aplicação do cliente.
Mas, há outros participantes no fórum com melhor visão sobre o tema e eu não tenho um domínio satisfatório de ambas as tecnologias (banco de dados e aplicação cliente).
Té+.