Bom antes que alguem fale, sim ja pesquisei arduarmente sobre o assunto que irei introduzir, e o mais incrivel: ou existem topicos mto infantis com pessoas que nao sabem nada(desculpe nao estou querendo ser presuncioso) ou acham q sabem … ou assuntos avançandos que geralmente se disvirtuam.
vamos ao interessa.
por favor o exemplo que irei colocar é infantil porem, na maioria dos casos sempre ta errado. deem uma olhada no forum ou no google e vcs veram.
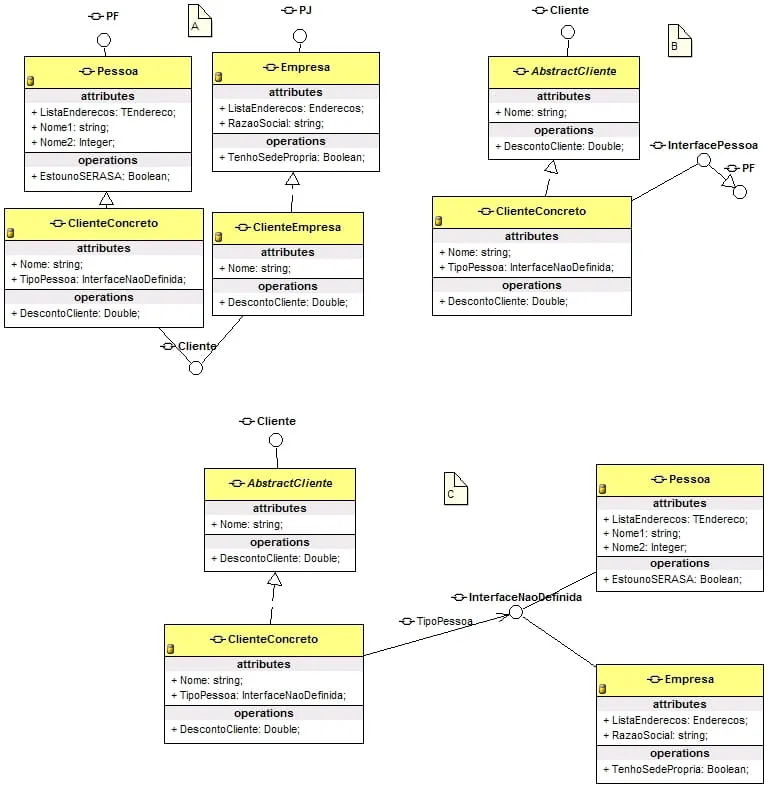
ipessoa
nome
sobrenome
TemFilhos
…
iEmpresa
razaosocial
TemFilial
Classe Pessoa implenta iPessoa
Nome
TemFilhos
…
iCliente
nome
DescontoDoCliente
ClientePessoa extents Pessoa e implementa iCliente
ClienteEmpresa extents Empresa e implementa iCliente
ja criei ClienteEmpresa e ClientePessoa pois o calculo de seus desconto sao diferentes, e logo adinte teram mais variações. Logo se a unica diferença fosse cpf e cnpj nao teria pq criar duas classes, porem na maioria dos exemplos a razao de ser ter duas classes para clientes é unica e exclusivamente cpf e cnpj q nao faz sentido nehum.
para mim nao me estender mto a questao é a seguinte
Classe OpVenda … essa classe tem um cliente que ira comprar alguma coisa, para essa classe oq importa é que quem vai comprar seja um cliente. Logo terei OpVenda.DefineCliente(iCliente cliente). e terei um OpVenda.DefineCliente.cliente_ID.
DefineCliente(iCliente cliente)
this.cliente = cliente
cliente_ID = cliente.ID
estarei passando como parametro no preenchimento da venda um ClientePessoa por exmplo.
Agora como faço quanto quero pesistir OpVenda?
como terei
apenas cliente_ID e uma variavel apontando para um interface iCliente
como irei carregar(pesistir) cliente se eu nao sei mais se ele é ClientePessoa ou CLienteEmpresa? e nao posso persistir uma interface
logo achei essa alternativa:
OpVenda.Carrear
iCliente this.cliente = new FactoryCliente.carregaCliente(thies.cliente_ID); //esse metodo retorna uma interface iCliente
//sendo que cliente_id ja esta persistido
FactoryCliente.carregaCliente(int cliente_ID) : iCliente
ClienteEmpresa ce = new ClienteEmpresa
if ce.carregar(cliente_ID) then
return := ce
else
ClientePessoa cp = new ClienteEmpresa
if cp.carregar(cliente_ID) then
return := cp
nao estou usando hibernate pois apenas quero endender se isso faz sentido.
Agradeço desde ja. desculpe pelos erros portugues, e desculpe a má implemntacao da sintaxe em java.