[quote=Lezinho][quote=Lezinho]
(…)não me refiro em momento algum a abstração de persistência(…)[/quote]
… como você pode notar Shoes, eu nãO estou me referindo a persistência, nem especifiquei que o usuário se referiu a ela. A história do usuário implica que toda vez (se e somente se) determinada entidade estiver “pronta” (tipada em “guardar determinados dados”) execute a tarefa X.
[/quote]
Exatamente, mas como eu falei no meu ost o fato de que o Repositório possui um método save() é um acidente. Quem troca o estado do objeto é ele mesmo, não uma entidade externa, então quem deve realizar uma lógica em decorrência desta troca deve ser avisado sobre o evento elo objeto.
Talvez eu não tenha sido claro: não, ele não tem adicionar(). Adicionar, salvar ou o que for só existem poque você precisa amntêr estado artificialmente, para o modelo de objetos todo objeto criado já está ‘adicionado’. O ‘adicionar’ do seu exemplo é meramente uma troca de estado.
Novamente: o Repository -pode ate ser, mas nao eh na minha ideia- não e o observador, o observador vai ser outro objeto que pode ser uma entity ou service.
Como falei, quem mantem o estado não é o Repository, é o objeto. Esse é o rincípio básico de Orientação a Objetos, objetos gerenciam seu estado e sofrem mudanças de acordo com estímulos externos. Quando o objeto muda d estado ele pode avisar outros objetos, sema entities ou services ou o que for, e esses tomam alguma atitude. No final das contas seu mecanismo de persistência tira uma foto do estado final e guarda no banco de dados, isso pode ser tão invasivo como repositorio.adicionar()/salvar() ou tão transparente quanto usar EJB3/Hibernate.
[quote=pcalcado]
A única maneira que eu vejo de usar specifications no meu exemplo (e é o que uso) é no caso (1) com a dupla QuryObject/Specification, que é uma aplicação do tipo (1). Se você fizer isso ainda cria uma dependencia entre os query objects e o domínio, caindo no mesmo problema do DAO vs Repository, então acho que não deve ser isso.
Como você faz exatamente? Retorna todos os objetos e aplica uma Specicication como se fosse um Visitor?[/quote]
Seguinte, o que as 3 solucoes que você apresentou tem em comum é obter uma SQL para executar a tal consulta. Atualmente na minha camada de infraestrutura (Repository<T>) eu tenho essa possibilidade de executar uma SQL, mas a sua construcao ocorre onde é a implementacao do repositorio.
1 - Aguém tem que fazer ResultSet <=> Domínio e esse alguém precisa conhecer o domínio (nem que seja por configuração). Onde você faz essa transformação?
2 - Alguém precisa gerar o SQL(ou HQL, ou EJBQL, o que for…), onde ele é gerado?
Pelo que entendi o SQL é gerado no repositório, mas acho que não é isso que você disse porque aí teríamos um objeto da camada de negócios sabendo sobre como gerar SQL. Uma forma de evitar isso é QueryObjects implementando Specifications, é isso que você faz?
Bom, o repositório como sendo, abstratamente, uma coleção de objetos em memória, adicionar ou remover elementos nesta coleção não me parece ser algo tão “acidental” ou distante do foco do negócio.
Usuários fazem buscas interessantes e relevantes para o domínio, em algo que eles acreditam armazenar informações (um repositório de dados). Introduzir mais dados ou remover, desta mesma coleção de informações não é algo que o usuário ignore, por vício de tratar com sistemas automatizados ou não.
Perder esse conhecimento e interação com os usuários não sei até que ponto é interessante.
O unico motivo para o reposit’orio ser introduzido como uma colecao em memoria eh porque essa eh a maneira mais facil de fazer um desenvolvedor pensar sobre ele. Essa 'e uma abstra’c~ao para o desenvolvedor, nao para o negocio.
Idealmente o repositorio seria capaz de buscar todos os objetos, mesmo os que ainda nao foram persistidos.
Se voce de fato tem um Repositorio de dados como um conceito de negocio, e nao apenas como uma abstracao acidental, ele provavelmente tem um nome como eu disse anteriormente. ContaCOrrente eh um repositorio consolidavel de transacoes bancarias por exemplo.
Eu acho que voce esta deixando vazar conhecimento de implementacao e limitacoes na modelagem para o negocio. Isso eh normal e se funciona para voce tudo bem, desde que nao se torne patologico. Isso eh apenas mais uma manifestacao da Law of Leaky Abvstractions
O cliente me pediu que implementasse aquela tarefa “X” daquela forma: “Quando eu clicar no botão SALVAR, execute a tarefa X e salve os dados”.
Ele não sabe o que é abstração dos dados de uma forma de persistência. Mas eu e a equipe sabemos que a tarefa X é totalmente pertinente a entidade a ser persistida, portanto, ela é um método daquela entidade.
classe EntidadeDoDominio{
//atributos
...
public void tarefaX(){
}
}
… é da linguagem dele e faz parte das interações com o sistema clicar no botao “SALVAR”. Ele pode ter inclusive esta operação sobre esta entidade, em mais de um ponto do sistema.
Inclusive, antes dele pedir que se executasse a “tarefa X”, os eventos sobre os botões estavam assim nas páginas:
Com a alteração que o usuário pediu, eu não mexeria nas páginas (já que se tornou um requisito realizar a tarefa antes de persistir os dados), mas faria:
class RepositorioDaEntidadeDoDominio implements Repositorio{
@In Dao dao;
public void adiciona(EntidadeDoNegocio entidadeDoNegocio){
entidadeDoNegocio.tarefaX();
dao.persist(entidadeDoNegocio);
}
}
Isso resolve o problema para todas as chamadas que eu tinha para o evento de “Salvar” sobre essa entidade, disparado pelo usuário. E ao meu ver não feriu camadas alguma (tudo continua no domínio). É claro que essa não é uma prática para todas as situações, inclusive não é tão comum, mas eu puxei essa discussão pelo seu post seu com o Moscoso de ‘nunca’ atribuir uma regra no repositório. Na prática, isso pode em determinados casos ajudar e muito…
Pelo lado técnico da coisa, minha entidade acaba sendo o observável ‘pelo Repositório’ (ok, sei q vc disse que para vc não seria assim). Já que o objeto gerencia seu estado, o repositório é informado (pela UI ou facade) que o estado do objeto é ‘pronto’ e dispara a ação, assim como o usuário definiu.
Isso não é regra, e meus repositórios não estao cheios disso, mas já usei, sem dor na conciência.
Exemplificando Shoes (com pseudo-códigos ?) , como você resolveria de forma eficiente isso?
Você está novamente falando sobre coisas que eu não falei, peço para que se atenha a este detalhe. Eu não falei em Camadas (minha discussão com o Moscoso é sobre algo completamente diferente do que voê está falando) e nem que Repositório nunca tem regra de negócio. É a segunda vez que eu repito isso e peço para que você se lembre disso.
[quote=Lezinho]Ok amigo, vamos ao seguinte:
O cliente me pediu que implementasse aquela tarefa “X” daquela forma: “Quando eu clicar no botão SALVAR, execute a tarefa X e salve os dados”.
Ele não sabe o que é abstração dos dados de uma forma de persistência. Mas eu e a equipe sabemos que a tarefa X é totalmente pertinente a entidade a ser persistida, portanto, ela é um método daquela entidade.
classe EntidadeDoDominio{
//atributos
...
public void tarefaX(){
}
}
… é da linguagem dele e faz parte das interações com o sistema clicar no botao “SALVAR”. Ele pode ter inclusive esta operação sobre esta entidade, em mais de um ponto do sistema.
Inclusive, antes dele pedir que se executasse a “tarefa X”, os eventos sobre os botões estavam assim nas páginas:
Com a alteração que o usuário pediu, eu não mexeria nas páginas (já que se tornou um requisito realizar a tarefa antes de persistir os dados):
[/quote]
Eu não sei quão ‘pseudo’ é seu código mas vejo um problema aí: você não está usando uma Camada de Aplicação. Se você usasse uma Camada de Aplicação não precisaria se preocupar tanto com “eu não mexeria nas páginas”.
Resolver resolve, assim como não usar conceitos de DDD ou mesmo não usar orientação a objetos também resolve. Por isso que falei antes: se funciona para você ótimo. O ponto é que o repositório não é o lugar para esta regra, imho, simplesmente porque o fato que um objeto vai ser adicionado é simplesmente uma limitação técnica, não um conceito de negócio. Ainda que fosse implementar algo procedural desta forma eu optaria por um Service do o repositório.
Desculpe mas isso não tem nada de observer. Primeiro porque não há mudança de estado, emv ez de o estadoe star no objeto como se espera em um programa OO ele está sendo manipulado por outro objeto, e por isso meu comentário sobre código procedural acima.
[quote=Lezinho]
Exemplificando Shoes (com pseudo-códigos ?) , como você resolveria de forma eficiente isso?[/quote]
Vou omitir a interface porque ela é irrelevante nesta discussão, assuma que o código abaixo é chamado pela Camada de Aplicação.
Supondo que quando um pedido eh processado (“salvo”) eu preciso gerar e persistir um outro objeto chamado NotaFiscal.
Modelo mais procedural para parecer mais com a estratégia que você adotou:
class WorkflowPedido{
void terminarProcessamento(Pedido p){
p.terminar();
emissor.gerarNotaFiscalPara(p);
//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estrutura
repositorioPedidos.adiciona(p);
}
}
class EmissorNotas{
void gerarNotaFiscalPara(Pedido p){
NotaFiscal nf = new NotaFiscal(p);
nf.algumaCoisa();
//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estrutura
repositorioNotaFiscal.adiciona(nf);
}
}
Como falei a abordagem acima segue o mesmo princípio procedural mas remove a lógica do Repositório. Já é ruim o Repositório ter que adicionar objetos, adicionar lógica de negócios a iso é misturar uma necessidade técncia com uma necessidade do modelo.
Mesmo adotando este estilo, como falei antes, vale a pena investigar uma forma mais inteligente de fazer o Workflow, a mudança de estado pode merecer ser modelada através de um Service mais coerente e coeso.
Vamos tentar fazer algo mais OO:
class Pedido{
public void terminar(){
this.status = Status.PROCESSADO;
for(Observador observador: observadores) observador.notificar(this);
}
}
class WorkflowPedido{
Pedido criarNovoPedido(){
//isso estaria melhor numa factory
Pedido p = new Pedido();
p.adicionaObservador(emissorNota);
}
void terminarProcessamento(Pedido p){
p.terminar();
//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estrutura
repositorioPedidos.adiciona(p);
}
}
class EmissorNotas{
public void notificar(pedido p){
if(p.status() == Status.PROCESSADO)
gerarNotaFiscal(p);
}
void gerarNotaFiscalPara(Pedido p){
NotaFiscal nf = new NotaFiscal(p);
nf.algumaCoisa();
//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estrutura
repositorioNotaFiscal.adiciona(nf);
}
}
Dessa forma quem controla a mudança de estados e a notificação dos interessados é o objeto. O Service sequer precisa sabe 9se você extrair numa fábrica, como sugerido) quem observa o objeto e você pode adicionar novos comportamentos facilmente.
Resumindo:
Eu não falei que Repositório não tem regra, não sei de onde você tirou isso, falei que dificilmente vai ter
Seu exemplo sente falta de uma Camada de Aplicação, acredito que isso faz com que a regra estar no Repositório seja algo natural para você
“Adicionar ao Repositório” é um requisito técnico derivado de uma limitação, não misturar regra de negócio com limitação écnica é uma boa idéia
Existem bilhões de maneiras de fazer isso sem colocar regras no repositório, maneiras mais ou menos OO
Se funciona para você e se você acredita que consegue software de boa qualidade fazendo isso ótimo. Arquitetura (e design) é sobre pessoas, não sobre religião
Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.
1)Eu não afirmei nada sobre alguma menção sua a “camadas”, me referi a repositórios, mais precisamente sobre o conteúdo acima. Você não mencionou ‘nunca usar regras’, mas é o que da-se por entender com a afirmação (a não ser que fosse levado em conta algo ‘sobrenatural’). Caso o entendimento não for esse, minha desculpas …
2)A necessidade de uma camada de aplicação é questionável. De início, a única coisa a ser feita era apenas guardar o estado do objeto em um meio persistente (sim, por limitação da tecnologia). Poderia criar uma façade para a aplicação, a fim dela chamar o repositorio, mas em uma relação 1 para 1, não vejo ganho. Com a mundança no requisito, eu deveria certificar que todos os pontos do sistema que fazem chamada ao meio persistente para aquele objeto tbm fossem invocados pela mesma façade (para valer do requisito), o que pode não ser verdade.
3)O Segundo exemplo seu é bem modelado. Não tenho nada o que criticar a respeito. Contudo note que o objeto com o comportamento ‘terminar’ ja estaria previamente modelado, e assim adicionar observadores a ele de fato não exige muita complexidade (o que é ótimo). Mas em uma situação que onde a ação da aplicação era somente preservar o estado de um objeto, refatorar a modelagem para este código pode não ser tão simples e a contextualização do negócio pode não ser cabível… por exemplo se seu objeto de domínio, diferente da classe Pedido que você modelou, não possuisse algo como ‘terminar’.
4)Quanto ao código ser mais ou menos procedural, veja que a única coisa que o repositório fez em meu exemplo é uma delegação, ele não alterou o estado de ninguém, se tarefaX fazer isso não tem problema (alterar o estado)… faz parte do comportamento da entidade… ele é um método da entidade (o que não esta legal é de onde isso é invocado, isso concordo, é discutível). Esta certo que por conveniência ele agregar um requisito a mais do que simplesmente guardar dados pode não parecer bacana, mas o único motivo que achamos isso é por convenção.
Phillip, não estou tirando qualquer razão sua, pelo contrário, o único ponto que não consigo sacar é a questão de regras não poderem ser invocadas pelo repositório, só isso. Apesar de não ser natural ou comum, eu nao erradico essa possibilidade ou vejo quebra de paradigmas… Você esta vendo algo de errado que eu não vejo. Vou reavaliar algumas ações e modelagem, assim como convesar com os desenvolvedores, de qualquer forma, obrigado pela conversa.
[quote=emerleite]Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.[/quote]
Depende do requisito Emerson. Como venho dizendo, não defendo que a prática de atribuir responsabilidades a mais para um repository seja algo natural, mas dependendo do contexto ela é válida (ou não, de acordo com a visão do Shoes).
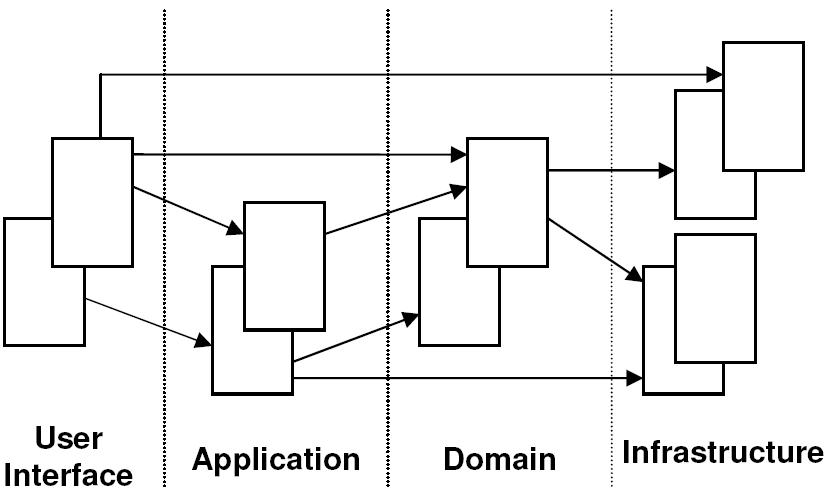
Sobre acessar um repository pela UI, de acordo com o diagrama da Layered Architecture proposto pelo DDD (na primeira página desta thread), não fere qualquer preceito.
Mas amigos, não estou falando pra ninguém sair recheando repositories de códigos… não é essa a idéia…
Você está colocando palavras na minha boca. Voc6e acabou de descrever insistentemente um exemplo de regras de negócio que eu não considero serem naturais para um repositório. Se você acha seu sistema sobrenatural…
Tudo é questionável mas fazer um acesso da interface (se ainda fosse do controller era uma camada de aplicação mesclada com apresentaçao) direto para o domínio é algo muito estranho a menos que você use naked objects. Se você não acha, ok.
O ponto todo em se adotar uma técnica como Domain-Driven Design é facilitar este tipo de refatoração. Se você precisa mudar boa aprte do seu código para adotar umd esign que você acha razoável então para mim seu código tem problemas (que, como já falei, começam pela aus6encia da camada de aplicação).
O que seu método diz é “quando a entidade X atingir o estado Y eu digo para ela fazer Z”. Toda essa lógica pertence à entidade e quando você tira dela está separando estado e comportamento.
[quote=Lezinho]
Phillip, não estou tirando qualquer razão sua, pelo contrário, o único ponto que não consigo sacar é a questão de regras não poderem ser invocadas pelo repositório, só isso. Apesar de não ser natural ou comum, eu nao erradico essa possibilidade ou vejo quebra de paradigmas… Você esta vendo algo de errado que eu não vejo. Vou reavaliar algumas ações e modelagem, assim como convesar com os desenvolvedores, de qualquer forma, obrigado pela conversa.[/quote]
Desculpa Alessandro mas você está sendo extremamente defensivo e isso tem prejudicado muito qualquer evolução nessa discussão. Se você discorda de mim e quer discutir ótimo, se discorda e não quer discutir ótimo também, o que não dá é para manter esse tom “sobrenatural”.
[quote=pcalcado]
Você está colocando palavras na minha boca.[/quote]
Minha intenção foi justamente o contrário … como quotei no ultimo post.
… você disse que não achava normal um repositorio ter isso. Se o codigo que postei era sobrenatural então você passa a acreditar na possibilidade de um repositório ter regras ?
Tanto o estado quanto o comportamento estavam na entidade, reveja o código. Se uma façade invocasse o comportamento você acharia errado?
Usei o termo ‘sobrenatural’ como uma brincadeira mesmo para a sua afirmação de que estava dizendo coisas que você não disse, o que ao meu ver, coisa sua também defensiva e sem fundamento (em vista do que você mesmo disse). Do resto, acho que concordo com o fato de que a thread deixou de ‘somar’ (coisa que você tbm não disse, mas dá-se por entender pelo ultimo post).
[quote=Lezinho][quote=emerleite]Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.[/quote]
Depende do requisito Emerson. Como venho dizendo, não defendo que a prática de atribuir responsabilidades a mais para um repository seja algo natural, mas dependendo do contexto ela é válida (ou não, de acordo com a visão do Shoes).
Sobre acessar um repository pela UI, de acordo com o diagrama da Layered Architecture proposto pelo DDD (na primeira página desta thread), não fere qualquer preceito.
Mas amigos, não estou falando pra ninguém sair recheando repositories de códigos… não é essa a idéia…[/quote]
Pra não prolongar nem criar outras respostas que falem a mesma coisa, vou usar uma que foi dada logo em seguida.
Este diagrama é utilizado no livro para explicar Camadas apenas -que é um dos capítulos introdutórios. Se for seguí-lo ao pé da letra sua interface ode chamar diretamente um DAO ou mesmo classs JDBC/Hibernate, que estão na Camada de Infra-Estrutura.
Se você usa esse diagrama pra defender a sua idéia dos repositórios, qualquer um poderá usa-lo para defender a idéia de criar uma JSP com código acessando o banco via JDBC, quebrando todas as camadas. Afinal de contas, o desenho mostra claramente uma seta partindo de User Interface direto para Infrastructure. :shock:
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
[quote=Lezinho]Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.[/quote]
Isolado e sem razão de existir.
Partindo do princípio que você quer um Domain Model -do contrário não há nem porque envolver conceitos de Domain-Driven Design na conversa- se você trata seu banco de dados como persistência e faz isso é a mesma coisa em efeitos práticos que deixar todo os atributos das suas classes como públicos: Você quebra completamente o encapsulamento. Num Domain Model o unico meio legítimo de se chegar aos dados é através do modelo, os dados são apenas uma fotografia do modelo. Se você acessa à fotografia sem passar pelo modelo está acessando dados sem passar pelos objetos.
[quote=Lezinho]Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.[/quote]
Desculpe mas isso já saiu da argumentação para defesa a qualquer custo. Não faz o menor sentido o que você está falando. Para que ter todo o trabalho de organizar as coisas se você vai direto na fonte de dados passando por cima de tudo?
Com esses argumentos não faz mais sentido continuar essa discussão, IMO.