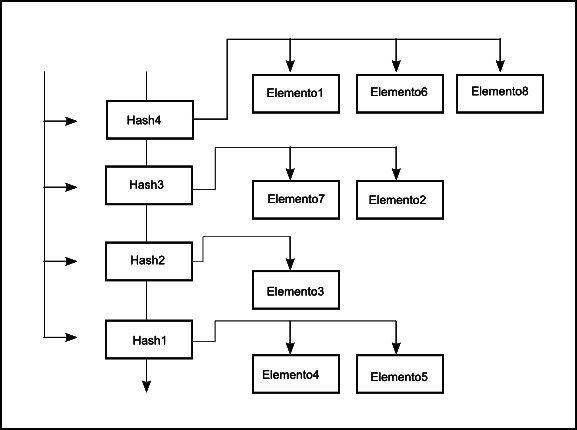
Bom, pesquisando na internet eu cheguei a conclusão que o hashset é mais rápido pra procurar os objetos dentro dele porque ele “categoriza” os objetos pelo hashcode.
A analogia que mais me deixou claro isso foi a de uma agenda de telefones aonde cada letra do alfabeto seria uma chave e cada registro seria um elemento a ser categorizado. A vantagem em fazer isso parece obvia, se eu precisar pesquisar um nome que começe com a letra D, eu posso pular todos os registros do A, do B e do C.
O problema é que li que o ideal ao se implementar um hashcode é evitar ao maximo hashcodes iguais pra que ela se torne eficiente. Ora pois, se eu tiver uma agenda e em cada letra da agenda só tiver um registro, qual a vantagem isso vai me dar ? eu vou gastar praticamente o mesmo tempo que eu gastaria caso os registro estivessem simplesmente listados em ordem alfabetica.
Isso me leva a crer que estou perdendo algum detalhe q é o que realmente torna o hashset mais rápido na pesquisa de elementos. O que seria ? porque é mais facil pro hashset comparar hashcodes pra me entregar o elemento do que pra uma arraylist comprar os proprios elementos ? seria porque fazer uma comparação entre tipos primitivos é mais rapido do que chamar o equals de cada elemento ?