Antes que alguém diga que estou tentando adotar soluções complexas para um problema simples, este projeto tem como finalidade o estudo de orientação a objeto.
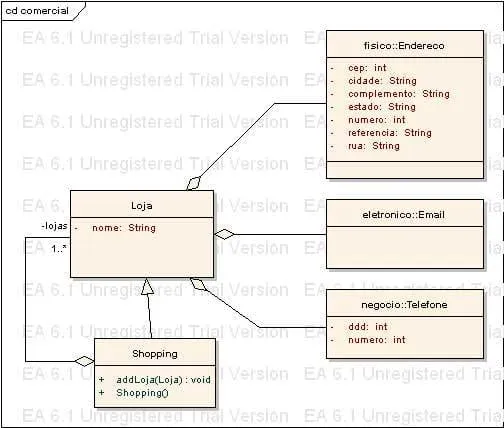
Baseado-se no modelo de domínio em anexo e na utilização dos padrões: Modelo de domínio, Camada de Serviço e Repositório.
Requisito:
O meu cliente deseja ter a facilidade adicionar lojas ao shopping.
“Ooo como é difícil persistir e recuperar objetos de forma sadia para a orientação a objeto!”
Dentre várias soluções que eu pensei vou citar 2 delas. E gostaria que vocês avaliassem não só as soluções mais também as contra-indicações que eu penso que elas possam me trazer.
1 solução: Fazer com que a coleção de lojas do shopping seja implementada como um repositório. Mas como eu persistiria o nome do shopping? Criar um repositório só para persistir o nome do shopping acho um pouco estranho. Eu tendo a ver repositórios como coleções e nome não é uma coleção.
2 solução: Criar uma camada de serviço para o shopping e criar um repositório para o shopping. Fazer com que a camada de serviço gerencie a persistência do shopping (A camada de serviço ira chamar métodos como repositorioShopping.atualizar(shoppingL)). Mas imagina eu adiciono uma loja no shopping e chamo o repositorioShopping.atualizar(shoppingL), vou ter que fazer varias verificações para saber o que alterou no shopping “Nada eficiente eu acho”. Posso também colocar no repositório o método repositorioShopping.addLoja(shoppingL.getLoja(_idNovaLoja)), acho que essa solução não fica lá muito cheirosa, ainda mais porque acho que não faz muito sentido ficar com lojas em memória. Tendo em vista isso não, faz sentido eu adicionar uma loja no shopping e depois coloca-la no repositório e ainda sim ela continuar no objeto shopping em memória.
Se vocês quiserem me recomendar outras soluções, criticar as minhas, acrescentar algo nas minhas ou até citar fontes para estudo eu agradeceria muito!
[]s
Boa diversão!