Não elimina.
Porém, pode ser que o modo como a tabulação foi realizada não esteja de acordo com o padrão para o java (\t)
V
vhenrique
darlan, pode me explicar melhor o que quer dizer com tabulação ?
darlan_machado
Em geral, quando você cria um documento de texto em que determinados valores precisam ser posicionados de forma adequada, você separa os “elementos” usando a tecla tab e não a space.
Se quer um exemplo, no java, você pode fazer algo como:
Por acaso você não está fazendo nenhum replace do conteúdo da linha lida?
Posta o código completo da leitura do arquivo, pois o trecho que você postou sempre vai lançar uma exceção.
Você está salvando o valor lido em um arquivo e conferindo o conteúdo em algum editor the texto?
Se for o caso, pode ser que seu editor está renderizando o ‘\t’ como vários espaços em branco.
V
vhenrique
java.io.Filefile=newjava.io.File(path);nomeArquivo=file.getName();//Contandoquantaslinhashánoarquivo.
//----------------------------------------------------------------------logSistema="contagem de linhas.";java.io.FileInputStreamfileInputStream=newjava.io.FileInputStream(file);java.io.BufferedReaderbufferedReader=newjava.io.BufferedReader(newjava.io.InputStreamReader(fileInputStream));//LendoarquivoparaimportaçãologSistema="leitura do arquivo de importação.";while((linha=bufferedReader.readLine())!=null){
if(!gb.isEmpty(linha)){
O arquivo em si vem zipado, antes de realizar a leitura eu descompacto ele, salvo em uma pasta, pego o arquivo .txt para fazer a leitura, esse arquivo descompacto fica exatamente igual ao que eu descompactei por conta propria, achei que era o problema de tabulação mesmo, porém vi que o espaçamento são espaços simples mesmo e não “tab”.
PS: Não postei o restante do codigo pois é muito extenso e esse trecho é o que se usa como base para as demais partes do codigo, devido depender da variavel “linha”.
staroski
Não posta imagens, posta o código e formata com o botão </> é muito ruim ler código em imagens.
Em algum momento você está alterando o conteúdo das linhas.
Pode ser quando você descompacta ou em algum momento na sua leitura.
Sem ver o código completo não dá pra descobrir.
Como é seu código que descompacta o arquivo?
V
vhenrique
Não altero, somente descompacto.
Vlw pela dica, estou me adaptando a plataforma ainda.
staroski
Mas pra descompactar, você lê um InputStream do arquivo ZIP e grava num OutputStream do arquivo descompactado.
Como estás fazendo isso?
V
vhenrique
// Verifica se não existe a pasta temp e criajava.io.Filediretorio=newjava.io.File(caminhhoPadrao);if(!diretorio.exists()){diretorio.mkdir();}// Salva o arquivo .zip java.io.FilearquivoZip=newjava.io.File(caminhhoPadrao,nomeArquivo);fItem.write(arquivoZip);java.io.Filearquivo=null;// descompactar arquivo .ziptry{java.util.zip.ZipFilezip=newjava.util.zip.ZipFile(arquivoZip);java.util.Enumerationentries=zip.entries();while(entries.hasMoreElements()){java.util.zip.ZipEntryentry=(java.util.zip.ZipEntry)entries.nextElement();arquivo=newjava.io.File(diretorio,entry.getName());nomeArquivo=entry.getName();destino.put("Texto",nomeArquivo);gb.getExecScript("CorrigirCharset");nomeArquivo=destino.getString("TextoCharSet");origem.put("NomeArquivo",nomeArquivo);java.io.InputStreaminput=zip.getInputStream(entry);java.io.OutputStreamoutput=newjava.io.FileOutputStream(arquivo);byte[]buffer=newbyte[1024];intlen=0;while((len=input.read(buffer))>=0){output.write(buffer,0,len);}input.close();output.close();}zip.close();}catch(java.io.IOExceptionioe){origem.put("msgErro","Não foi possível descompactar o arquivo. Detalhes: "+ioe.getMessage());}
Dessa forma.
staroski
Legal, o problema não parece estar na descompactação.
Após descompactar, é feito alguma outra tratativa no arquivo descompactado?
Pergundo porque você tem uma chamada pra um tal de gb.getExecScript("CorrigirCharset");
Tem algum outro código que manipula seus arquivos antes de você ler as linhas?
Se não tiver, então minha sugestão é que realmente poste o código que faz a leitura dele.
V
vhenrique
Então, não passa por nenhuma tratativa antes da leitura, aquele gb.getExecScript é referente ao nome do arquivo, não tem contato com o arquivo em si.
Como eu havia postado logo acima, o código referente a leitura é esse:
try{
java.io.Filefile=newjava.io.File(path);nomeArquivo=file.getName();//Contandoquantaslinhashánoarquivo.
//----------------------------------------------------------------------logSistema="contagem de linhas.";java.io.FileInputStreamfileInputStream=newjava.io.FileInputStream(file);java.io.BufferedReaderbufferedReader=newjava.io.BufferedReader(newjava.io.InputStreamReader(fileInputStream));//LendoarquivoparaimportaçãologSistema="leitura do arquivo de importação.";while((linha=bufferedReader.readLine())!=null){
if(!gb.isEmpty(linha)){
logSistema="importação do VA.";auxIe=linha.substring(0,12); inscricaoEstadual=auxIe.substring(0,3)+"."+auxIe.substring(3,6)+"."+auxIe.substring(6,9)+"."+auxIe.substring(9,12);
O restante do código é somente obtendo os valores respectivos da variavel “Linha”.
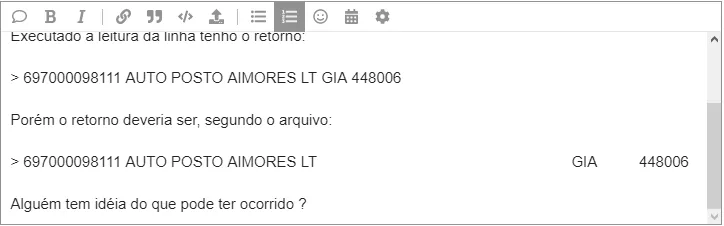
O problema é que no arquivo as posições das informações estão de um jeito e na hora de fazer a leitura do mesmo, esta de outro, que é aquela questão dos espaçamentos. Impossibilitando que eu estipule um padrão de recorte das informações.
darlan_machado
Está usando java 8 ou superior?
Se sim, existe a classe Files. Ela permite ler o arquivo todo, de uma vez, e gerar um array de String que representam as linhas:
List<String>linhas=Files.lines(File.getPath());
V
vhenrique
Sim java 8, vou tentar utilizar essa classe e te dou um retorno.
V
vhenrique1 like
Cara meu exitamento em postar o reste do código, foi minha perdição.
O codigo estava complemente correto no que diz respeito a leitura, porém em dado momento ao tentar recortar um trecho da string utilizando substring, ele estourava o tamanho. Acontece que o parametro “endIndex” estava incorreto, dai na pressa em resolver nem me atentei que poderia ser isso pois ao exibir a linha estava diferente da do arquivo. Peço desculpas, e agradeço o empenho.