Boa Noite Pessoal.
Estou desenvolvendo um trabalho capaz de simular Automatos Deterministicos. O programa deverá receber como parâmetros de LINHA DE
COMANDO o caminho para dois arquivos, da seguinte forma:
simulador arquivo1 arquivo2
Onde, arquivo1 indica o caminho para o arquivo de descrição do autômato (conforme
padrão a seguir) e arquivo2 indica o caminho para um arquivo que contem uma palavra
por linha, que o seu programa deve informar se é reconhecida ou não pelo autômato
definido pelo arquivo1.
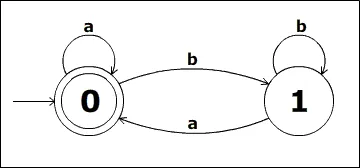
O padrão do arquivo de descrição do autômato será descrito a partir do exemplo abaixo
(os números das linhas, à esquerda, não fazem parte do arquivo, estão presentes
somente para identificação da linha na descrição a seguir):
- digraph D{
- rankdir=LR;
- start [shape=point];
-
start > 0;
-
0 > 0 [label=a];
-
0 > 1 [label=b];
-
1 > 0 [label=a];
-
1 > 1 [label=b];
-
0 [peripheries=2];
- }
Estou com duvida em como ler este arquivo citado acima e ir preenchendo as variaveis internas no sistema.
Agradeço a ajuda.