Olá pessoal,
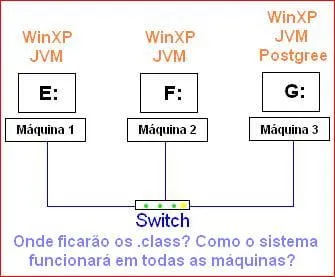
:arrow: Tenho a seguinte arquitetura de Hardware:
- São 3 computadores ligados entre eles por um switch;
- Estes estão mapeados na rede Windows, ou seja, máquina 1 é a unidade E:, máquina 2 é a unidade F:\ e máquina 3 é a unidade G:;
- Todas elas são desktop’s (nenhuma é servidor) sendo que a máquina 3 (G:) tem como nomenclatura “servidor”;
- Não existe mais nada ligado neles, ou seja, não há Internet nem outros computadores falando com eles.
:arrow: Agora tenho a seguinte estrutura de Software: (dentro dessa rede local de computadores citada acima)
- Todas estão com Windows XP e JVM instalados e na máquina 3 (G:) existe também o Postgree.
:arrow: Tenho a seguinte atividade:
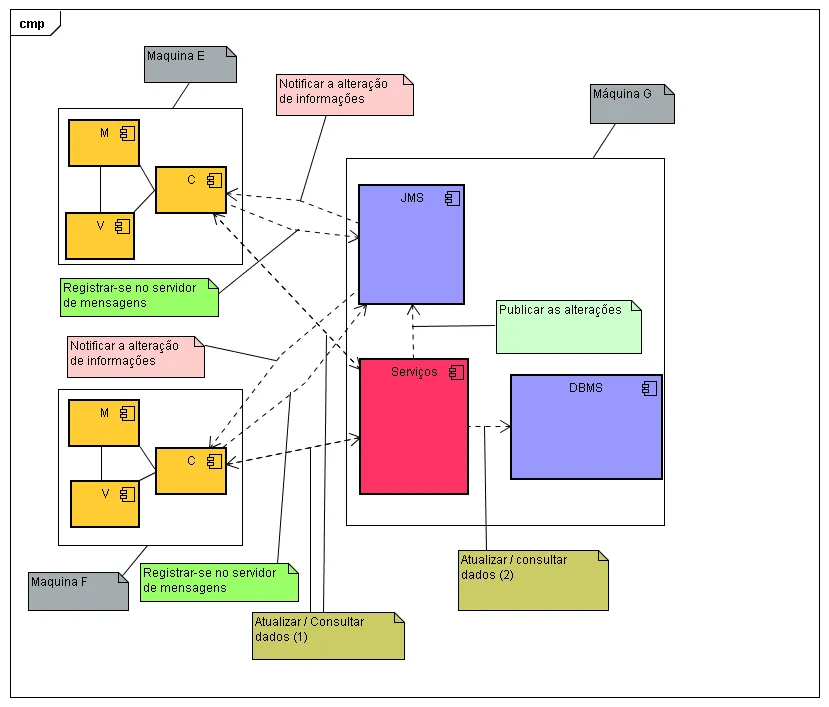
Estou fazendo um sistema de cadastro de cliente que utilizará o Postgree. Esse sistema terá uma arquitetura Swing com MVC e tem que rodar nessas três máquinas usando o banco de dados Postgree que está na máquina 3 (G:). Com relação ao banco de dados, não tenho preocupação pois configuro as máquinas 1 e 2 para falarem com o banco na máquina 3 via ODBC.
:?: Então tenho a seguinte pergunta:
Agora quanto ao software (os class), como vou fazer? Preciso colocá-los em cada máquina ou somente na máquina 3 (G:) e chamo ele pela rede mesmo?
Um detalhe importante é que o MVC não pode ser quebrado, ou seja: Se uma classe do modelo mudar ele deve ser refletido em todas as máquinas, caso essas estejam com uma visão que usa essa classe do modelo alterado. [color=blue](Veja imagem abaixo em anexo)[/color]
Fico no aguardo por respostas, [color=red] muito obrigado![/color]