Estou desenvolvendo uma aplicacao que utiliza o Apache Lucene como engine de buscas.
Estou tendo dificuldade para realizar busca em campos nao analisados e que estão armazedos no indice.
Por exemplo:
campos enum que representam alguma situacao;
valores booleanos;
O problema é que a busca utilizando esses campos não está retornando o resultado correto.
Por exemplo:
uma busca por um valor booleano
A consulta correta seria nomeDoCampoDoIndice:false, mas nao é isso que está rolando. Para retornar os resultados corretos a consulta tem que ser feita dessa forma nomeDoCampoDoIndice:falsee
O mesmo acontece num campo “situacao” onde o valor que está armazenado no indice é “ativo”, para encontrar o resultado correto, o valor para a consulta tem que ser “ativoo”.
Estou começando a achar que é algum bug da versão do Lucene…
Os indices estão sendo indexados utilizando o Analyzer org.apache.lucene.analysis.br.BrazilianAnalyzer.
Testei no Luke, utilizando a classe KeywordAnalyzer os documentos foram encontrados com a consulta situacao:false.
Segundo a documentação do Lucene, as consultas devem ser usando a mesma implementação da interface Analyzer usado na criação do indices.
Será que pode ser algum problema na implementação da BrazilianAnalyzer que falhe para pesquisar os campos armazenados no indice ?
renanpto
Ufa, descobri o que acontece para o Apache Lucene funcionar dessa maneira, é um BUG no código para o Brasil.
Baixei o fonte e fui acompanhando a execução via debug para chegar no ponto onde zica…
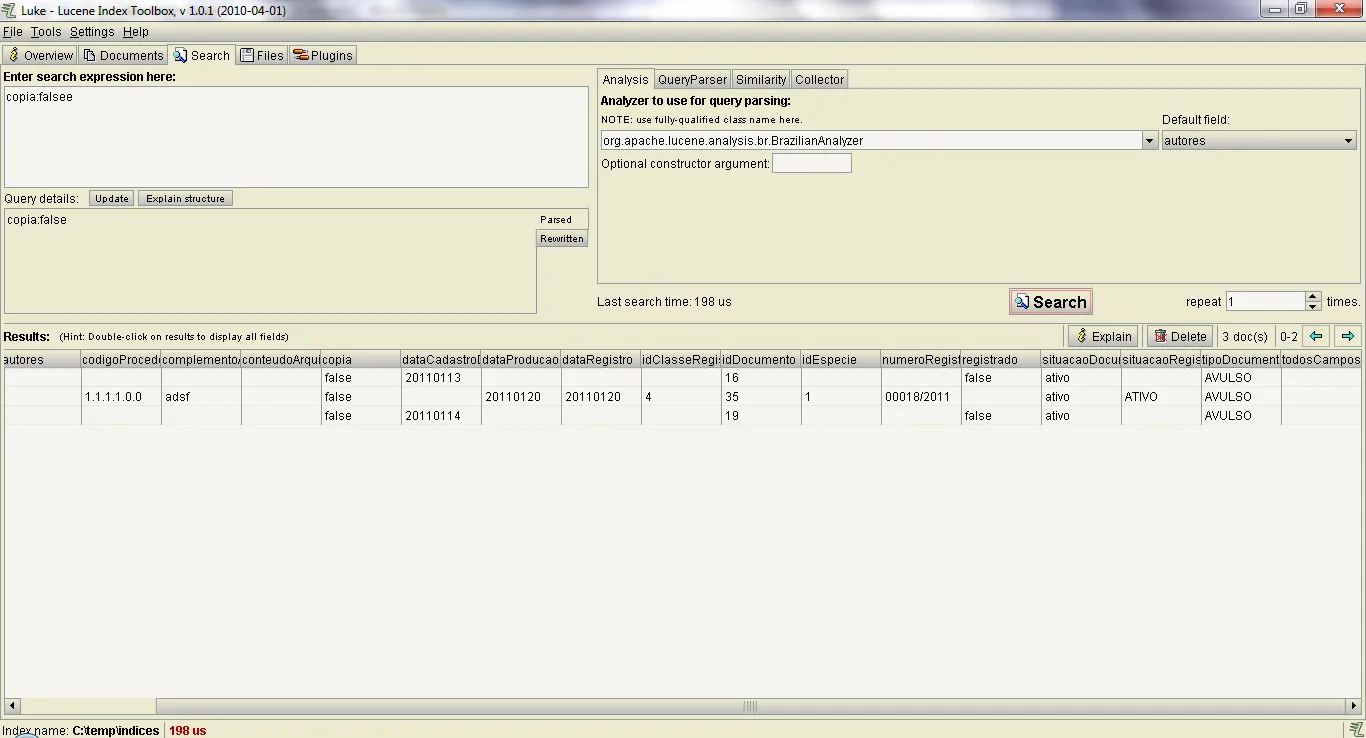
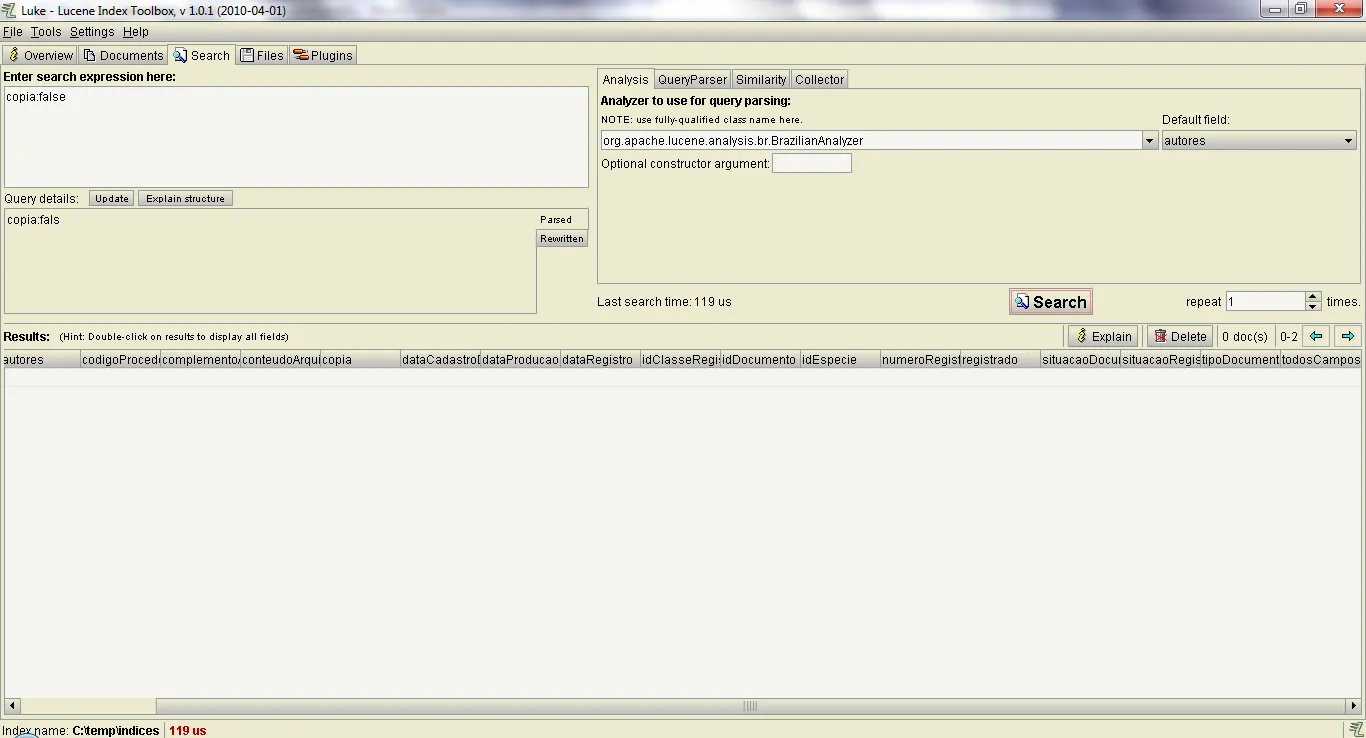
No Luke é possivel ver o bug. No anexo 1, é a imagem com a execução da consulta copia:false. E no segundo a execução da consulta copia:falsee
Acho q já arrumei esse bug, mas estou usando a última versão do Lucene 3.4.0
Ainda não achei um Luke que funcione com a mesma.
Vou mandar para eles (ela simplesmente remove a acentuacao, algumas stop word e transforma tudo para minusculo).
[]s
renanpto:
Ufa, descobri o que acontece para o Apache Lucene funcionar dessa maneira, é um BUG no código para o Brasil.
Baixei o fonte e fui acompanhando a execução via debug para chegar no ponto onde zica…
No Luke é possivel ver o bug. No anexo 1, é a imagem com a execução da consulta copia:false. E no segundo a execução da consulta copia:falsee
Acho q já arrumei esse bug, mas estou usando a última versão do Lucene 3.4.0
Ainda não achei um Luke que funcione com a mesma.
Vou mandar para eles (ela simplesmente remove a acentuacao, algumas stop word e transforma tudo para minusculo).
[]s
renanpto:
Ufa, descobri o que acontece para o Apache Lucene funcionar dessa maneira, é um BUG no código para o Brasil.
Baixei o fonte e fui acompanhando a execução via debug para chegar no ponto onde zica…
No Luke é possivel ver o bug. No anexo 1, é a imagem com a execução da consulta copia:false. E no segundo a execução da consulta copia:falsee