Ok eu achei outros posts no forum e descobri que para se comunicar com um programa se pode usar o windowsAPI, mas existe como fazer o contrario, extrair informacoes de algum programa ou janela? Se sim alguem tem algum exemplo? pq eu tenho um outro posto que eu to precisando pegar algumas informacoes de um site que puxa as informacoes de um xml, formata com um xls e manda pra tela, ou seja eu nao tenho como pegar essas infromacoes no source e nao to conseguindo acessar o xml que o site puxa as informacoes. Qualquer ajuda em bem vinda!! vlew
Como pegar informacoes de um programa
S
20 Respostas
B
Sink0,
O ideal com certeza seria trabalhar com o xml, porque não esta conseguindo pega-lo?
Estou procurando um jeito de pegar dados de uma tela como gostaria, já fiz isso em VB, a um bom tempo atrás. E achei interessante a pergunta.
Abs,
Bruno Tafarelo
S
Bom eu tenho um outro post, mas ele ja ta muito confuso entao vou descrever todo o meu problema aqui. A minha situaçao eh o seguinte, eu estou tentando desenvolver um programa que opere sozinho na bolsa de mercadorias futuras. O programa que ira fazer os calculos de o que deve ser feito, a principio eu estou desenvolvendo em C++. O meu problema esta no programa que faz a interface, ou seja captura informacoes para fazer os calculos e inputa as ordens que o programa em C fala que devem ser feitas. O lugar de que eu vou pegar as informacoes é de um homebroker especializado em mercado de contratos futuros (isso nao eh importante entender caso voce nao tenha entendido). Esse site so pode ser acessado pelo IE pois um requisito eh o XML Parser 3.0. Nao adianta eu passar os links para voces pois voces nao poderao navegar pelo mesmo pois é necessario um login e senha. O problema de logar no site ja foi resolvido com httpclient do apche, e para isso existem muiots exemplos no forum. Bom como eu estou tentando resolver meu problema por partes, eu comecei tentando capturar as ordens de compra e venda disponiveis que se econtrarm em um parte do site. O codigo fonte dessa pagina é o seguinte:
<HTML>
<HEAD>
<META NAME="GENERATOR" Content="Microsoft Visual Studio 6.0">
<title>OFERTAS: wing09</title>
<link href="/negociacao/CSS/27.css" rel="stylesheet" type="text/css">
<script type="text/javascript" src="/negociacao/JS/funcoes.js"></script>
<script>
//parametros
var iCulture = 1;
var sEmpresa = "CD";
var sInstrumento = "WING09";
var sApplicationPath = "/negociacao";
var sSkin = "27";
function Search(code)
{
if (code == '' ) {
alert("Código do instrumento inválido (" + code + ").");
return;
}
window.location.href = "../cotacoesEmpresa.asp?ativo="+code;
}
function SendToForm(qty, value)
{
try
{
alert("Função indisponivel");
}
catch(e) {
alert("Erro: " + e);
}
}
//body (scope)
{
//General
var xmlelem, xmlnode, count;
var maxItm = 30;
var arrType = new Array("S","B");
//consulta de compra
var strXmlIn = "<BOOK><INST NAME=\"" + sInstrumento + "\" EXCH=\"" + sEmpresa + "\" QTTO=\"100\"/></BOOK>";
var strXmlErr = "<BOOK><INST NAME=\"" + sInstrumento + "\" EXCH=\"" + sEmpresa + "\"><ORDERS TYOR=\"S\"></ORDERS><ORDERS TYOR=\"B\"></ORDERS></INST></BOOK>";
//executar consulta
var xmldoc = executaXML(sApplicationPath+"/_xml/xml_consulta_livro_ofertas.asp", strXmlIn);
//se nao retornou nada, exibir xml default
if(xmldoc.xml == '')
{
xmldoc = new ActiveXObject("MSXML2.DOMDocument");
xmldoc.async=false;
xmldoc.loadXML(strXmlErr);
}
//preencher o grid se houver menos de 20 ofertas
for (var j=0; j < arrType.length; j++)
{
count = xmldoc.selectNodes("//BOOK/INST/ORDERS[@TYOR='" + arrType[j] + "']/ORDER").length;
if ( count >= maxItm )
continue;
xmlnode = xmldoc.selectSingleNode("//BOOK/INST/ORDERS[@TYOR='" + arrType[j] + "']");
if ( xmlnode != null )
{
for (var i = 0; i < (maxItm - count); i++)
{
xmlelem = xmldoc.createElement("ORDER");
xmlelem.setAttribute("PRCE","0");
xmlelem.setAttribute("QTOR","0");
xmlnode.appendChild(xmlelem);
}
}
}
}
function CreateBook(cType, xmlDocument)
{
//clonar estrutura
var xmlCopy = xmlDocument.cloneNode(4);
//selecionar nodes de venda para exclusao
var xmlNodeList = xmlCopy.selectNodes("//BOOK/INST/ORDERS");
for (var i = 0; i < xmlNodeList.length; i++)
{
if (xmlNodeList[i].attributes.getNamedItem("TYOR").nodeValue.toUpperCase() == cType )
{
var parent = xmlNodeList[i].parentNode;
parent.removeChild(xmlNodeList[i]);
}
}
//posicionar no root
var rootnode = xmlCopy.documentElement;
//adicionar data e hora atual
var oDataHora = xmlCopy.createElement("dataHora");
rootnode.appendChild(oDataHora);
rootnode.lastChild.text = '05/01/2009 10:29:48';
//adicionar skin
var oSkinAttrib = xmlCopy.createElement("skin");
rootnode.appendChild(oSkinAttrib);
rootnode.lastChild.text = sSkin;
//adicionar flag
var oTopTenAttrib = xmlCopy.createElement("TopTen");
rootnode.appendChild(oTopTenAttrib);
rootnode.lastChild.text = "1";
//aplicar XSL ao XML
var content = applyXSL(xmlCopy.xml, sApplicationPath + "/_xsl/xsl_consulta_livro_ofertas.xsl", iCulture, sApplicationPath);
//exibir
document.writeln( content );
}
</script>
</HEAD>
<BODY topmargin="0" bottommargin="0" leftmargin="10" rightmargin="10" scroll="no">
<table width="100%" border="0" cellpadding="0" cellspacing="0">
<tr>
<td colspan="2"><img src="/images/negociacao/skins/27/transp.gif" width="1" height="5"></td>
</tr>
<tr>
<td width="354" class="CON_TXT_PRETO">
<SPAN class=CON_TXT_PRETO>OFERTAS DE wing09 EM 05/01/2009 10:29:48</SPAN>
</td>
<td width="1" align="center" valign="bottom"><img src="/images/negociacao/skins/27/divideCinza.gif" width="1" height="11"></td>
<td height="29" align="right">
<table cellspacing=0 cellpadding=0 border=0>
<tr>
<td><a href="JavaScript:Search('wing09');"><img src="/images/negociacao/skins/27/btVoltar.gif" alt="Atualizar" border="0"></a></td>
<td><a href="JavaScript:window.document.location.reload();"><img src="/images/negociacao/skins/27/btTool_refresh.gif" alt="Atualizar" border="0"></a></td>
<!--td><img src="/images/negociacao/skins/27/btTool_NegDia.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/negocios.asp');" alt="Negócios do Dia" border="0" style="cursor:hand;"></td-->
<td><img src="/images/negociacao/skins/27/btTool_OrdPend.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/ordens.asp');" alt="Ofertas pendentes" border="0" style="cursor:hand;"></td>
<td><img src="/images/negociacao/skins/27/btTool_ModOferta.gif" OnClick="JavaScript:window.open('/negociacao/bmf/negociacoes/ordens.asp');" alt="Modificar oferta" border="0" style="cursor:hand;"></td>
<td><a href="JavaScript:window.close();"><img src="/images/negociacao/skins/27/btTool_close.gif" alt="Fechar" border="0"></a></td>
</tr>
</table>
</td>
</tr>
<tr><td class="DivCinza"><img src="/images/negociacao/skins/27/transp.gif" width="1" height="1"></td></tr>
<tr><td><img src="/images/negociacao/skins/27/transp.gif" width="1" height="10"></td></tr>
</table>
<table border="0" cellspacing="0" cellpadding="0" width="100%" height="92%">
<tr>
<!--PANEL LEFT-->
<td width="50%" valign="top">
<div class="scrollFull">
<span id="spnBuyOffers">
<script>CreateBook("S", xmldoc);</script>
</span>
</div>
</td>
<!--PANEL LEFT-->
<td> </td>
<!--PANEL RIGHT-->
<td width="50%" valign="top">
<div class="scrollFull">
<span id="spnSellOffers">
<script>CreateBook("B", xmldoc);</script>
</span>
</div>
</td>
<!--PANEL RIGHT-->
</tr>
</table>
</BODY>
</HTML>
A imagem da tela do site eu vou deixar anexado a esse post. Ok no outro post que eu fiz o thingol me explico que na verdade o site pega as informacoes de um xml atravez de um Xpath e depois formata elas com um Xls. O endereco da tela inicial do site é [url]https://wtr.bmf.com.br[/url] e pelo que eu entendi no codigo acima, o endereco do xml é [url]https://wtr.bmf.com.br/negociacao/_xml/xml_consulta_livro_ofertas.asp[/url]. Caso e tenha interpertado o codigo erroneamente me corrijam por favor. Quando eu tento pegar o codigo fonte desse xml com o seguinte programa:
package webp;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.NameValuePair;
import org.apache.commons.httpclient.methods.PostMethod;
public class Main {
public static void main(String[] args) {
try {
//Esse Primeiro site eh o que eu tenho que logar
String url = "https://wtr.bmf.com.br/Autenticacao/SMLoginIBroker.fcc?TYPE=33554433&REALMOID=06-0ea14422-cef7-4d33-b467-0734805081ef&GUID=&SMAUTHREASON=0&METHOD=GET&SMAGENTNAME=$SM$Rlq1KK%2bTjmanrmkO%2bWkztYGagAIeD0fRFWN4cb08AryeECePlRWNZcA%2b3YdN0qOL&TARGET=$SM$https%3a%2f%2fwtr%2ebmf%2ecom%2ebr%2fnegociacao%2f_xml%2fxml_consulta_livro_ofertas%2easp";
HttpClient client = new HttpClient();
PostMethod method = new PostMethod(url);
List params = new ArrayList();
params.add(new NameValuePair("USER", "MeuUsoario"));
params.add(new NameValuePair("PASSWORD", "MinhaSenha"));
method.setRequestBody((NameValuePair[]) params.toArray(new NameValuePair[params.size()]));
client.executeMethod(method);
// Esse, é onde, pelo o que eu entendi pelo codigo fonte que eu postei acima, de onde sao retiradas as informacoes.
method = new PostMethod("https://wtr.bmf.com.br/negociacao/_xml/xml_consulta_livro_ofertas.asp");
client.executeMethod(method);
String page = method.getResponseBodyAsString();
System.out.println(page);
} catch (Exception e) {
e.printStackTrace();
}
}
}
O programa nao retorna nada, e esse programa ja foi testado para outras partes do site e outros sites e funciona direitinho. Se eu tento entrar no xml diretamente com o IE, eu recebo a seguinte mensagem na tela:
he XML page cannot be displayed
Cannot view XML input using style sheet. Please correct the error and then click the Refresh button, or try again later.
--------------------------------------------------------------------------------
XML document must have a top level element. Error processing resource 'https://wtr.bmf.com.br/negociacao/_xml/xml_consulta_...
E caso eu tente olhar o codigo fonte, vem a seguinte mensagem de erro:
The XMl source file is unavailable for viewing.
Bom basicamente esse seria o meu problema... EU mudei o nome do post para ficar mais adequado a minha pergunta. E mais uam coisa, o XLS que ele usa eu consigo acessar, mas ele nao eh de grande utilidade neh...
Eu estava pensando se existe algum modo de eu consguir capurar tudo que o browser esta fazendo ou seja, quando ele pega as informacoes do xml, teria algum modo de eu pegar essas informacoes dele? Outra coisa, eh possivel integrar javascript com java, por que dai eu podera tentar rodar o mesmo codigo que o IE roda. Outra coisa, com o httpclient do apache eu consigo inputar infrmacoes no site no objeto que eu quiser, mas existe como fazer o contrario? Ou seja capturar tais informacoes direto de um objeto como uma tabela? Bom qualqer ajuda é bem vinda!! Valew!!
A tela do site se encontra em anexo.
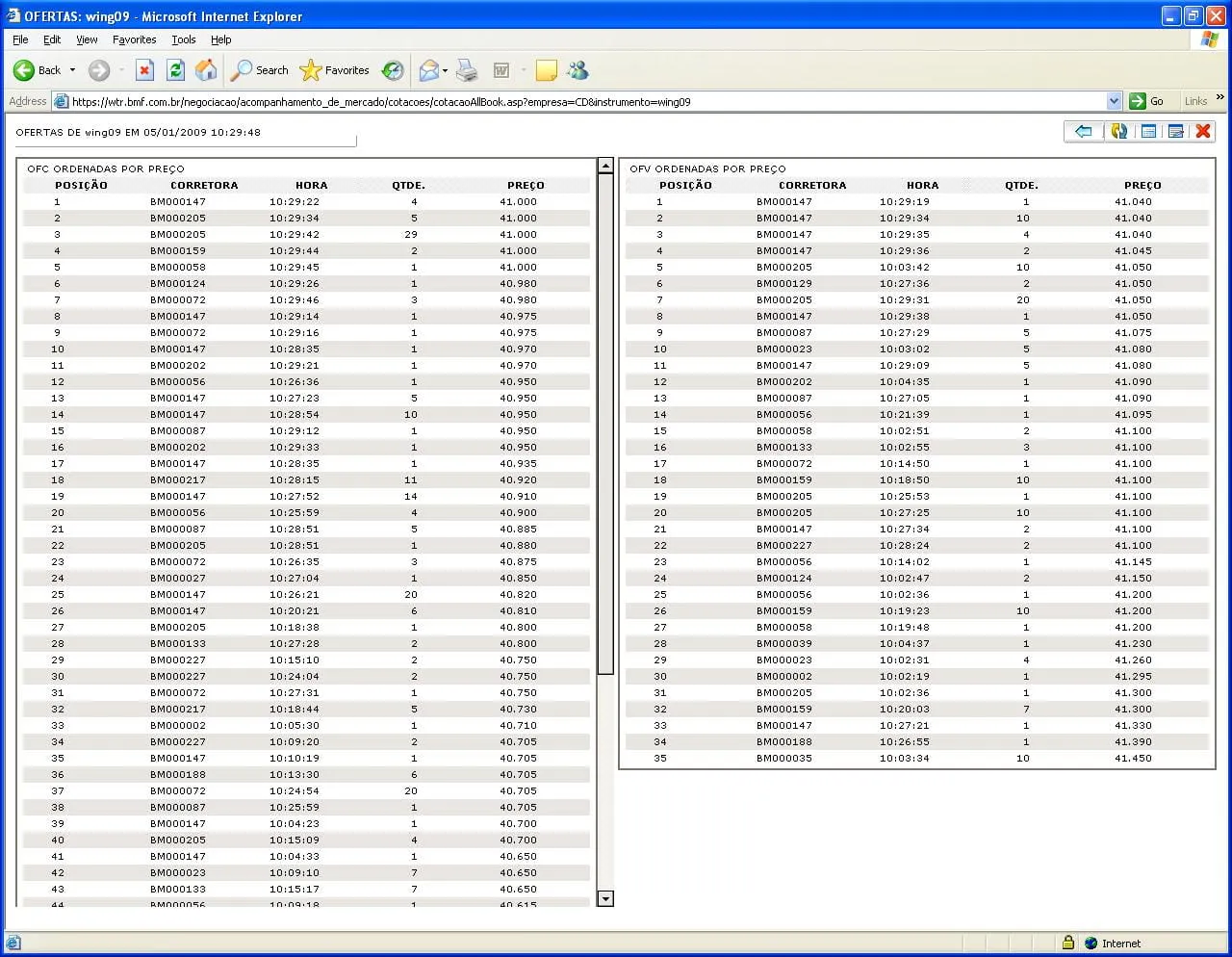
T
Você está tentando pegar informações do WTR (Web Trading) da BM&F diretamente?
Acho que você vai ter é de falar com alguém da BM&F.
Dependendo do que você quer fazer, não é permitido pelas condições de uso deles que estão no contrato do WTR, e se detectarem um padrão de uso fora do normal, eles podem cancelar o login que você está usando. OK?
S
Entao, eu falei com a area responsavel da BMF, e eles falaram que funciona assim, eles disponibilizam um sinal para a coretaroa com as informacoes, e o modo que ela passa para os clientes e de responsabilidade dela. Caso esse xml seja o sinal que a bmf passa para as corretoras, entao eu provavelmnte nao vou poder ter acesso a ele mesmo, mas caso eu consiga pegar essas mesmas inrformacoes de outra forma nao teria nenhum problema. Afinal as informacoes que eu quero nao sao diferentes das que eu ja tenho, eu so quero recebelas de outra forma. EU tentei ligar para area responsavel a corretora , mas o kra nao tava la. Se eu der sorte els tem algum tipo de wbservices que eu possa utilizar. Mas eu acho poco provalvel. Mas de qualquer maneira alguem tem alguma outra ideia de como pegar essas informacoes. vlew pela ajuda!!
PS: Eu a muito tempo tinah feito um modo beeeem tosco de fazer isso automatizando o mouse e o teclado, mas com c++. funcioava… mas era beeeeeem tosco haha, e deixava o computador completamente inutilizavel so sendo util para isso…
B
B
S
Como eu estou no trabalho, eu nao pude olhar direito o javadoc mas caso voce ou alguem ja tenha usado essa biblioteca que vc me passou, ela retira todas as informacoes do texto em si do codigo fonte? Ow nao ela interpreta o que o codigo fonte esta fazendo? No meu caso ela conseguiria interpretar a tabela que foi feita? Eu vou tentar montar algo em casa esse fim de semana para ver isso… mas agora eh impossivel fazer algo pq eu nao trabalho com programacao, ou seja nao tenho nada aquo…
S
So um perguntinha, nao sei se algum ja trabalho com isso, ou se eh possivel… Existe alguma maneira de mapear o flow de inrformacoes que ocorre com o meu browser? Ou agum modo de mapear a memoria e ver as informacoes que sao mostradas na tela do meu browser? Caso alguem ja tenha visto algo parecdio que eu possa pegar essa informacao que eu preciso indiretamente eu agadeco!!.. Vlew!!
S
Galera eu acho que vou abordar a coisa d eum modo diferente, e bem mais tosco se falando de programacao, mas pelo como as coisas tao indo eu nao vejo outra maneira. Eu so nao sei se o que eu quero fazer eh possivel. Eu abri so site no IE e salvei ele nao mao como txt, dai quando eu vou olha ro txt tao la os valores que eu quero, nao de um modo bonito, mas tao e as informacoes sao completamente faceis de serem pegas com substring. Agora a minha duvida eh o seguinte eu precisava fazer uma aplicacao que fizesse os seguintes passos:
1 - Abrisse o IE e entrasse na pagina do wtr. (Isso eu sei que eh possivel e ja vi varios topicos de como faze-lo)
2 - Logar pelo IE no wtr
3 - Esperar carregar a pagina
4 - Salvar a pagina como txt
5 - fechar o IE
Fazer isso ciclicamente e automaticamnte.
Dai depois disso, tendo o txt tudo fica beeem mais facil.
Alguem sabe se isso que eu quero fazer eh possivel? O Java eh a linguagem ideal para faze-lo?
Caso seja possivel, se alguem tiver algum codigo exemplo, ou puder me dar algumas referencias eu seria grato.
Obrigado!! VLew!
B
Sink,
Baseado no projeto que passei HtmlParser, você vai resolver seu problema. Deu uma fuçada nele e gostei.
Montei um exemplo que abre a url, e te retorna todo o código, mas você pode ir navegando entre os elementos e tudo mais.
package testes;
import java.net.URL;
import org.htmlparser.Node;
import org.htmlparser.Parser;
import org.htmlparser.util.NodeIterator;
import sun.net.www.protocol.http.HttpURLConnection;
public class ParsePage {
public static void main(String[] args) throws Exception {
URL url = new URL("http://www.google.com.br");
Parser parser = new Parser(new HttpURLConnection(url, null));
Node node;
for(NodeIterator it = parser.elements(); it.hasMoreNodes(); ) {
node = it.nextNode();
System.out.println(node.getPage().getText());
}
}
}
Espero ter ajudado.
S
Eu nao estou em casa entao nao posso testar aqui, mas so para ter certeza, esse codigo ele puxa o codigo fonte da pagina? por que ser for isso eu no maximo vou conseguir o codigo postado acima… que nao possui as informacoes que eu preciso ja que ele eh um javascript que puxa as informcoes do tal xml que eu nao consigo pegar o source… Isso se eu entendi direito o que vc fez pq o meu conhecimento eh meio limitado neh… vlew ae!!
B
Sink,
Pelo que pude entender da documentação, ele pega o “resultado” streaming da URL e não o código fonte da página.
Mas como esse é um caso um pouco especifico e não conheço agora nenhuma URL que seja igual o seu caso, não posso te afirmar.
Mas sua pergunta foi muito boa…
S
Bom eu realmente vou tentar isso… se der certo vai ser MUITO BOM!!! hehe Mas so por conhecimento, e para garantir, alguem sabe se existe algum modo de proceder pela maneira alternativa que eu descrevi acima? Abrindo o browser e salvando o txt?
Vlew pela ajuda ae!!
B
Sink,
Para abrir um programa qualquer, basta a linha abaixo:
Runtime.getRuntime().exec("C:\\Arquivos de programas\\Internet Explorer\\iexplore.exe www.google.com.br");
E para que o IE abra com uma página, basta passar como parametro para o IE o site.
S
Hmmm eu estou trabalhando como o html parser mas nao consegui muita coisa ainda… provavelmente eu nao estou sabend usar… eu usei o codigo que voce me passou mas nao seu muito certo por euquanto… mas eu vou tentando. E ok dessse modo eu posso abrir o IE, mas voce sabe como fazer os outros passos? Logar no site pelo IE e salvar a pagina em txt no IE? Vlew pela ajuda ae !!!
B
Cara,
Os outros passos fico te devendo, mas…
Para logar, veja no formulário de logon (código fonte) a propriedade action da tag form e o nome do campos de usuário e senha. Pegando isso, você pode tentar concatenar na url esses dados e o usuário e senha por exemplo:
URL = "www.google.com.br"
URL Atenticada = "www.google.com.br/logon.jsp?user=bruno&password=tafarelo"
Agora, para fechar salvar a página do IE só conhecendo alguma coisa da API dele, para ver se é possível. Mas, derrepente você conseguiria encontrar a página que quer nos diretórios de cache do IE.
Bom, estou lhe passando essas informações, mas é contra minha vontade… rs Não acho que deva ir por esse lado, mas se quer…
Agora, no código que lhe passei, você vai pegar o código fonte da página, veja se nesse código fonte, tem todos os dados que quer, ai você pode fazer de 2 maneiras:
1 - Usar os métodos da classe String para quebrar o código e pegar as informações, por exemplo: substring
2 - Usar os métodos da API do HTMLParser para navegar no código e pegar as informações (eu iria por aqui).
S
Essa eh bem a questao, o codigo fonte da pagina em qustao eu tenho ja... mas nao eh que eu nao consgio achar a informacao dentro dela, ela simplesmente nao existe. Isso acontece por que ela monta a tablea com javascript puxando os dados(que eh o que eu quero) do tal xml que eu nao consigo acessar(provavelmente pq ele nao aceita crossdomain). Eu tentei rodar o seu programa e em alguns codigos ele pega o codigo fonte, e em alguns ele retorna algumas coisas de estranho, anyway eu nao consgeui parsear ainda pq ele nao eh compativer com o httpclient do apache ou seja eu tenho que fazer o login com o bom e velho URLconnection que ja vem com o java, coisa que eu ainda nao montei o codigo para logar.... Mas entao sob o passo de autenticar pela barra de endereco. eu a tava tentando fazer isso, mas inicialmente pelo propriobrowser pq fica masi facil de testar mas no meu caso ja tem um monte de coisa concatenada no URL.
O enderco que aparece na barra referente a tela que eu tenho que logar eh: [url]https://wtr.bmf.com.br/Autenticacao/SMLoginIBroker.fcc?TYPE=33554433&REALMOID=06-0ea14422-cef7-4d33-b467-0734805081ef&GUID=&SMAUTHREASON=0&METHOD=GET&SMAGENTNAME=$SM$Rlq1KK%2bTjmanrmkO%2bWkztYGagAIeD0fRFWN4cb08AryeECePlRWNZcA%2b3YdN0qOL&TARGET=$SM$HTTPS%3a%2f%2fwtr%2ebmf%2ecom%2ebr%2fnegociacao%2facompanhamento_de_mercado%2fcotacoes%2fcotacaoAllBook%2easp%3fempresa%3dCD%26instrumento%3dwing09[/url]
O codigo fonte eh:
<html>
<head>
<title>Login</title>
<link href="CSS/login.css" rel="stylesheet" type="text/css">
</head>
<body leftmargin="0" topmargin="0" marginwidth="0" marginheight="0" background="../../images/autenticacao/bg_login_cinza.gif">
<script language="javascript">
//IE?
function msieversion()
{
var ua = window.navigator.userAgent;
var msie = ua.indexOf ( "MSIE" )
if ( msie > 0 )
return parseFloat (ua.substring (msie+5, ua.indexOf (";", msie )))
else
return 0
}
if (this.window!=top)
top.location.href = window.location.href;
//verificar se o browser �IE
var version = msieversion();
if ( version == 0 ) {
top.location.href = "requisitosns.htm";
} else if ( version > 0 && version < 5.1 ) {
top.location.href = "requisitosie.htm";
}
//verificar versao do XML Parse
try {
var doc = new ActiveXObject("MSXML2.DOMDocument.3.0"); //"3.0", );
} catch(e) {
top.location.href = "requisitosxml.htm"
}
</script>
<form name="LoginSM" method="post">
<table width="100%" height="100%" border="0" cellpadding="0" cellspacing="0">
<tr>
<td align="center" valign="middle">
<table width="580" border="0" align="center" cellpadding="0" cellspacing="0">
<tr>
<td>
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td width="6"><img src="../../images/autenticacao/aba_login_esq.gif" width="6" height="57"></td>
<td background="../../images/autenticacao/aba_bg_login.gif"><img src="../../images/autenticacao/logo_login2.gif" width="114" height="40" hspace="15"></td>
<td width="4" align="right"><img src="../../images/autenticacao/aba_login_dir.gif" width="4" height="57"></td>
</tr>
</table>
</td>
</tr>
<tr>
<td width="512" height="212" background="../../images/autenticacao/login_bg.jpg">
<table width="100%" height="166" border="0" cellpadding="0" cellspacing="0">
<tr class="CON_TXT_PRETO">
<td width="202" rowspan="4"><img src="../../images/autenticacao/transp.gif" width="201" height="19"></td>
<td colspan="2">DIGITE SEU LOGIN E SENHA E CLIQUE EM ENTRAR:</td>
<td width="25" rowspan="4"><img src="../../images/autenticacao/transp.gif" width="25" height="11"></td>
</tr>
<tr class="CON_TXT_PRETO">
<td width="80">LOGIN:</td>
<td width="281"><input name="USER" type="text" class="TEXTBOX_PRETO" style="width:230px;height:20px;"> </td>
</tr>
<tr class="CON_TXT_PRETO">
<td width="80">SENHA:</td>
<td><input name="PASSWORD" type="password" class="TEXTBOX_PRETO" style="width:230px;height:20px;"> </td>
</tr>
<tr class="CON_TXT_PRETO">
<td colspan="2" align="right"><input type="image" src="/images/autenticacao/bt_entrar.gif" width="113" height="25" hspace="5" align="absmiddle"><img src="/images/autenticacao/bt_cancelar.gif" onClick="javascript:window.history.back();" width="113" height="25" hspace="5" align="absmiddle"></td>
</tr>
</table>
</td>
</tr>
</table>
<img src="../../images/autenticacao/transp.gif" width="60" height="10">
<p> </p>
</td>
</tr>
</table>
<input type=hidden name=target value="HTTPS://wtr.bmf.com.br/negociacao/acompanhamento_de_mercado/cotacoes/cotacaoAllBook.asp?empresa=CD&instrumento=wing09">
<input type=hidden name=realm value="">
<input type=hidden name=smauthreason value="0">
</form>
</body>
</html>
Os campos que eu tenho que preencher sao USER e PASSWORD, pelo menos sao eles quando eu logo com o httpclient. Mas eu nao to conseguindo passar eles pela barra de endereco.
So para saber tal login deve encaminhar para: [url]https://wtr.bmf.com.br/negociacao/acompanhamento_de_mercado/cotacoes/cotacaoAllBook.asp?empresa=CD&instrumento=wing09[/url]
Vlew por toda ajuda... nao eh todo mundo que tem paciencia com pessoas sem conhecimentos como eu :lol:
B
Bom,
Acho que o concatenar não vai funcionar nesse caso, há um parametro na tag form que é o METHOD se for post, quer dizer que os dados não podem ir na URL concatenada, devem ir “anexados” que é muito mais lógico.
Bom, agora se o HtmlParser não esta pegando o streaming que é gerado pela página, eu fiquei curioso e vou dar um procurada nisso. Mas eu achei que ele pegasse o resultado.
Com certeza há uma maneira de se fazer isso.
B
Qual a url que você esta passando?
Se o conteúdo é gerado pelo JavaScript, você deve conseguir enxergar o xml, ou o serviço que gera o conteúdo para o javascript transformar.
Tenta achar essa URL e passar para o programinha.
S
Entao o que eu tentei pegar foi o codigo do xml que eu acredito, olhando o javascript que esta no meu segundo post, estar no https://wtr.bmf.com.br/negociacao/_xml/xml_consulta_livro_ofertas.asp. Isso pelo menso eu deduzi do javascritp que esta no source no site que se encontra a tabela. Se nao me engano eh isso nao? Eh so olhar a linha 47 do dogio do meu segundo post. Mas no entando , fazendo isso como httpclient o codigo vem em branco… E eu ja usei o httpclient pra pegar o source de outros sites e ele puxa direitinho… inclusive depois de logar… Dai eu foi trntar olhar o xml na mao mesmo la no browser eu tive os problemas descritos anteriormente. Eu nao tentiei usar o htmlparser na pagina que eu quero pq eu to com problemas para logar e usar ele ja que logar com httpclient nao ta sendo muito util. Alguma ideia?
Criado 8 de janeiro de 2009
Ultima resposta 13 de jan. de 2009
Respostas 20
Participantes 3
Alura O que é Python? — um guia completo para iniciar nessa linguagem de programação Acesse agora o guia sobre Python e inicie sua jornada nessa linguagem de programação: o que é e para que serve, sua sintaxe e como iniciar nela!
Casa do Codigo Engenharia de Prompt para Devs: Um guia para aprender a... Por Ricardo Pupo Larguesa — Casa do Codigo