Srs. @AbelBueno @drsmachado @esmiralha @rmendes08 , primeiramente obrigado pelas resposta.
Vou tentar colocar o cenário que está apresentando e o que eu tentarei fazer, para que todos tenham uma ideia.
Na empresa foi modelado, ao meu ver, de forma errônea, um relaciomaneto de produtos para que quando alterado o código do fornecedor um registro de elo entre eles e inserido e um relacionamento com chaves distintas é criado, conforme exemplo abaixo:
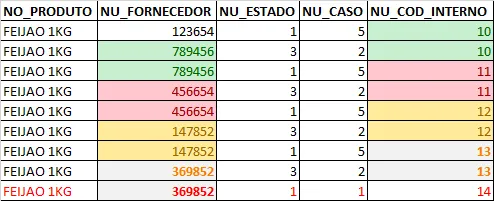
Supomos que temos este produto, Feijão, cadastrado em nossa base, da seguinte forma:

Se no próximo mês o nosso fornecedor, por algum motivo inusitado, alterar o NU_FORNECEDOR (que seria como um numero do produto na base de dados do fornecedor) eu não realizo apenas uma nova inclusão. Eu realizo o seguinte:
1 - Altero o NU_ESTADO E NU_CASO PARA 1 E 5

2- Crio um novo registro onde onde NU_ESTADO e NU_CASO sejam 3 e 2 mantendo o NU_COD_INTERNO

3- Cria-se um novo registro onde este terá a informação mais atual do produto com NU_ESTADO E NU_CASO sendo 1 e 1. Temos o seguinte resultado:

Observem que, quando tenho o relacionamento entre os códigos 1 e 5 com 3 e 2, utiliza-se o NU_COD_INTERNO como chave de relacionamento e, quando tenho relacionamento entre 3 e 2, utiliza-se NU_FORNECEDOR como chave de relacionamento.
Imaginem agora que este código pode sofrer alteracoes, como já vimos aqui, 16 vezes!
Em um exemplo de modificação de 3 vezes teremos nosso produto assim:
Objetivo do projeto:
Criar uma tabela de relaciomaneto inserindo todos os códigos que algum dia foram o mais atual do produto e criar uma coluna com os código atuais e anteriores.
O que consegui fazer, mas gostaria de melhorar a mais performance, foi criar uma lista assim:
Freqüência:
Procedimento será realizado uma vez por mês e , necessariamente, todos os registros devem ser lidos novamente.
Tamanho:
Temos aproximadamente 355 milhões de registro que serao divididos em 3 grupos utilizando o NU_ESTADO e NU_CASO para alocação em cada tabela.
Crescimento:
Crescimento médio de 30 mil registros mês.
Infra:
Contamos com uma maquina com 8 CPU em um total de 32 cores 120GB de memória hd SSD
Funcionamento:
Objetivo e rodar o processo localmente, standalone, para evitar para uma integração com outro servidor uma vez que o servidor e exclusivo para o software de integração. Interagir essa maquina com outra implicaria em procedimento de abertura de regra de firewall logo, preferimos deixar tudo centralizado uma vez que teremos durante este processo, a maquina com todos os seus recursos exclusivos para o processo. Contamos um um SQL Server 2016 com alta capacidade de comunicação.
Próximos passos:
Seguindo a ideia @pfk66, estou realizando os seguintes procedimento:
-
Realizados:
-
1- Em uma ferramenta de integração de dados, ja separei os códigos em grupos de 1e5 , 3e2 e 1e1 permanecendo com os registro que apenas, e apenas, tenham relacionamento entre eles pois, a base tem muito lixo.
-
Em andamento:
-
1- Jogando as informações extraídas para o SQL SERVER 2016 criando index pelas chaves. Apesar de repertisem, quando separamos em grupos, as mesmas tornam-se únicas em cada tabela.
Espero que as explicações possam ter tiradas as dúvidas e obrigado mais uma vez.