Galera, é o seguinte
Estava pesquisando sobre esses dois métodos de tokenização de Strings da API do Java e fiquei meio intrigado, pois tem gente que defende o StringTokenizer, que, apesar de ser mais velho e “engessado” ainda é mais performático. Outros (o que inclui a própria Sun) recomendam evitar o uso do StringTokenizer, e substituir pelo método split() da classe String, e eu não sei qual usar :?
A resposta mais óbvia seria o método split, visto que até na documentação da StringTokenizer há uma sugestão para utilizar o método split no lugar, mas eu ainda não vi tantos problemas com o StrinTokenizer (se bem que ainda não tive que dar manutenção em um código que o utiliza, o que deve pesar bastante rrsrsrs) e se o método split é tão recomendado, por que eles não o otimizaram para realmente ficar melhor que o StringTokenizer :?:
Vejam o que encontrei:
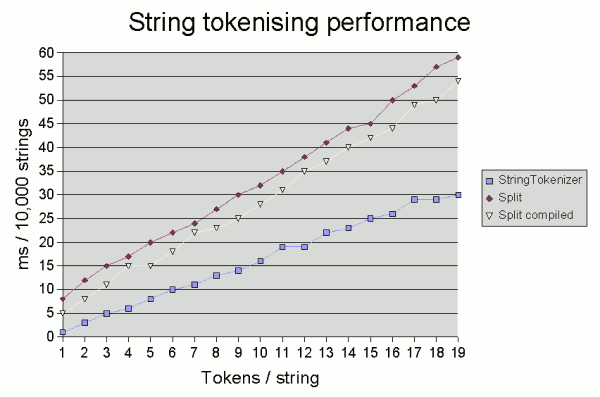
http://www.javamex.com/tutorials/regular_expressions/splitting_tokenisation_performance.shtml
[edit]
Esse site ainda recomenda o split “compilado”, do tipo
Pattern p = Pattern.compile("\\s+");
...
String[] toks = p.split(str);
[/edit]